AWS Supercharges Amazon ECS: Introducing Ultra-Fast Auto Scaling with High-Resolution Metrics
In a significant leap forward for containerized infrastructure management, Amazon Web Services (AWS) has announced a major upgrade to the Amazon Elastic Container Service (ECS) service auto scaling capabilities. By introducing support for 20-second high-resolution metrics, AWS is enabling developers to respond to traffic fluctuations with unprecedented speed, effectively closing the gap between demand spikes and infrastructure readiness. This update represents a critical evolution for cloud-native architectures that rely on sub-minute agility to maintain performance during peak traffic periods.
Main Facts: The Shift to 20-Second Precision
At its core, Amazon ECS service auto scaling acts as a dynamic safety net for containerized applications. Whether through predictive scaling for recurring patterns, scheduled scaling for known events, or target tracking for real-time adjustments, the system has historically relied on standard CloudWatch metric intervals. While effective, the standard 60-second polling resolution occasionally introduced a "lag" in scaling decisions, particularly for microservices experiencing rapid, unpredictable bursts of traffic.
The newly launched capability allows ECS services to utilize 20-second resolution metrics. This is not merely an incremental tweak; it is a fundamental reduction in the time-to-action for the entire scaling lifecycle. By moving to a 20-second heartbeat, the system can detect resource exhaustion—such as CPU or memory saturation—three times faster than previous configurations. This ensures that the infrastructure "breathes" in sync with the actual end-user experience, preventing latency degradation before it becomes noticeable to the customer.
Chronology: The Evolution of ECS Scaling
To understand the magnitude of this update, it is essential to view it within the broader timeline of AWS container orchestration:
- The Foundational Years: Since its inception, Amazon ECS provided basic scaling triggers, allowing users to define thresholds for CPU and memory. These were largely reactive and dependent on the standard 60-second CloudWatch reporting interval.
- The Era of Intelligent Scaling: AWS introduced Target Tracking, Predictive Scaling, and Scheduled Scaling, empowering developers to move away from static thresholds toward outcome-based scaling. During this phase, the bottleneck remained the metric reporting interval, which dictated how quickly the "Target Tracking" policy could calculate a deviation from the desired state.
- The Present (2024/2025 Transition): With the integration of high-resolution metrics, AWS has effectively removed the reporting interval as a primary inhibitor to rapid scaling. This development marks the transition from "responsive" scaling to "near-real-time" scaling, addressing the most demanding enterprise workloads that require near-instantaneous horizontal expansion.
Supporting Data: Benchmarking the Performance Gain
The impact of this update is best illustrated through the empirical data provided by AWS engineering teams during their benchmarking trials. The metrics reveal a stark improvement in the "Time-to-Ready" for new compute resources:
- Scaling Trigger Efficiency: Previously, the time required to trigger a scale-out event—from the moment a threshold was breached to the moment the command was issued—averaged 363 seconds. With the new 20-second high-resolution metrics, this has been slashed to just 86 seconds. This represents a 76% improvement (4.2x faster) in detection and reaction speed.
- End-to-End Provisioning: The total time required to scale and fully provision new tasks—the "cold start" to "productive" duration—has improved from 386 seconds to 109 seconds. This is a 72% improvement (3.5x faster).
These figures are transformative for applications that operate in highly volatile environments, such as e-commerce checkout systems during flash sales, financial trading platforms, or real-time gaming backends, where every second of latency translates into measurable financial loss.
The Operational Implications
The transition to high-resolution auto scaling brings three primary benefits to the architectural lifecycle of an application:
1. Enhanced Resource Efficiency
By scaling more granularly, organizations can maintain a tighter "headroom" buffer. In the past, engineers often over-provisioned resources to account for the 60-second delay in scaling. Faster auto scaling allows for lower baseline capacity without sacrificing the ability to handle sudden bursts, leading to significant cost optimizations in cloud spend.

2. Improved Service Level Agreements (SLAs)
During periods of high traffic, latency is the enemy. By shortening the time-to-scale, the infrastructure is better positioned to maintain consistent response times. This stability helps engineering teams adhere to stricter SLAs and SLOs (Service Level Objectives), ensuring that the user experience remains seamless even during the most aggressive traffic spikes.
3. Simplified Management
Despite the increased performance, the operational overhead remains minimal. The configuration process is integrated directly into the existing Amazon ECS console and AWS CLI workflows. Whether a team is using AWS Fargate, ECS Managed Instances, or standard EC2, the high-resolution metrics can be enabled with a simple toggle during service creation or via an update to an existing service.
Implementation Guide: How to Deploy
Transitioning to faster auto scaling is designed to be a non-disruptive process for existing services.
For New Services:
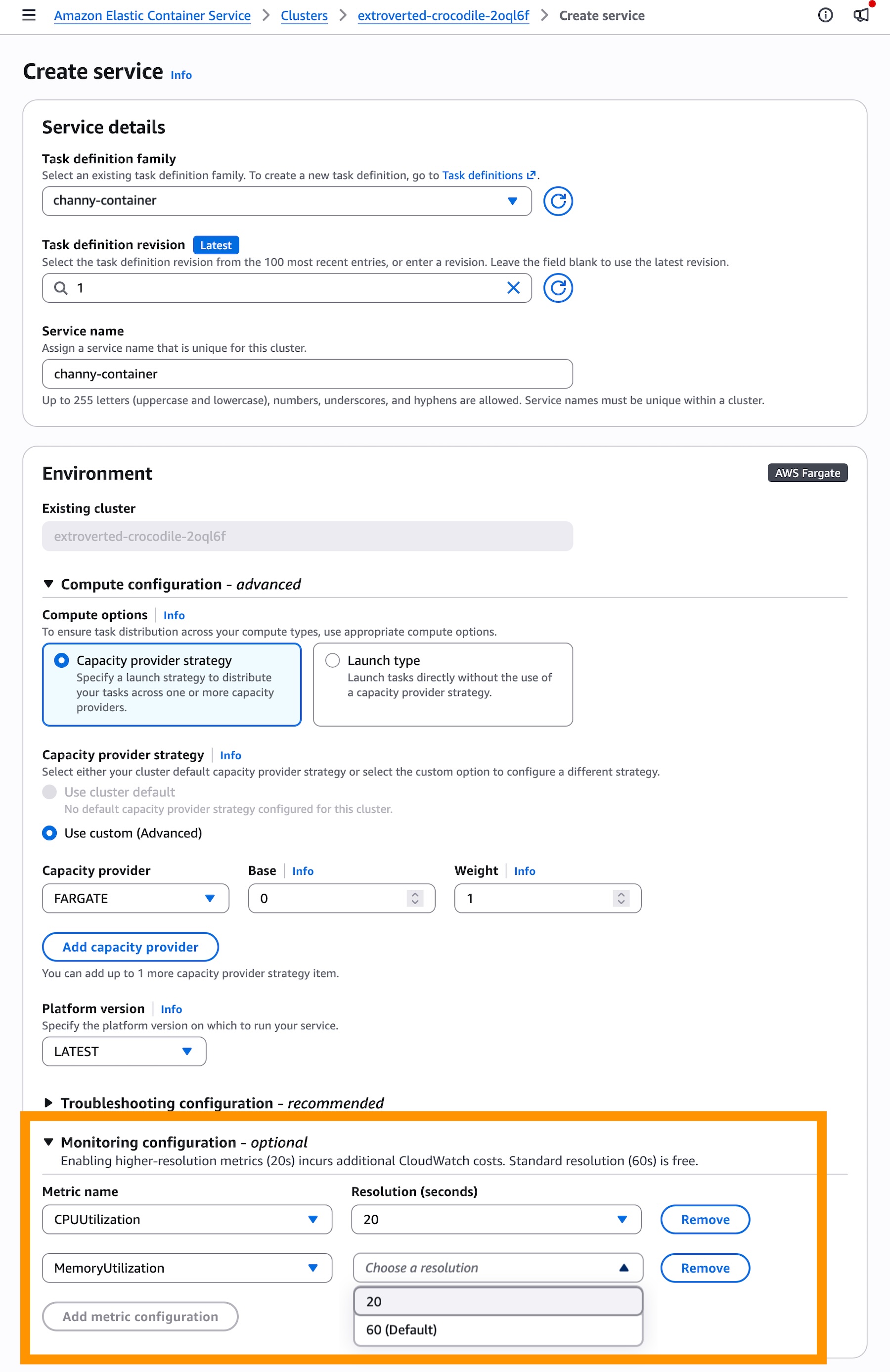
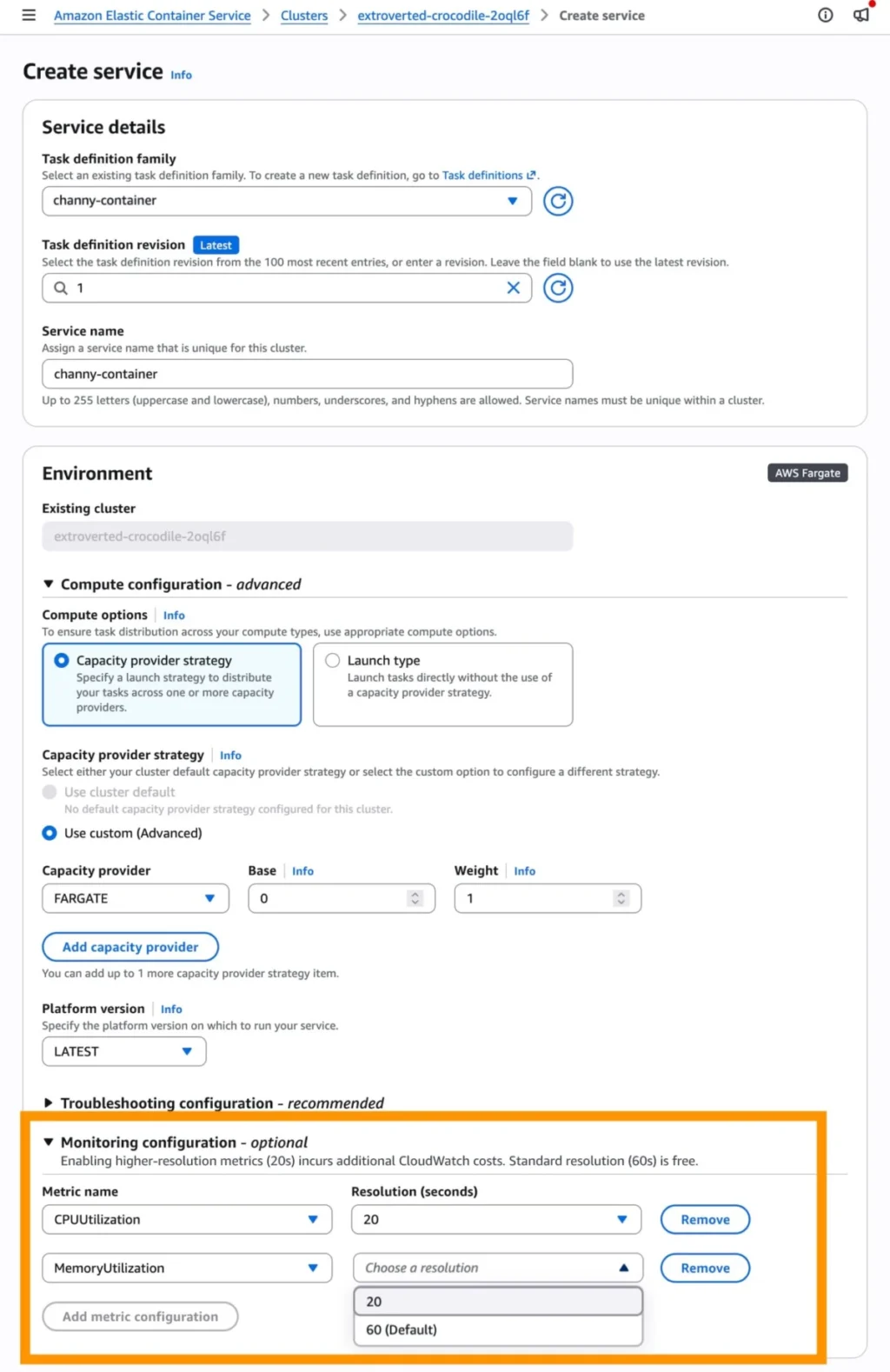
- Navigate to the Amazon ECS console.
- During the "Create Service" workflow, locate the Monitoring configuration section.
- Select the option to enable 20-second resolution metrics.
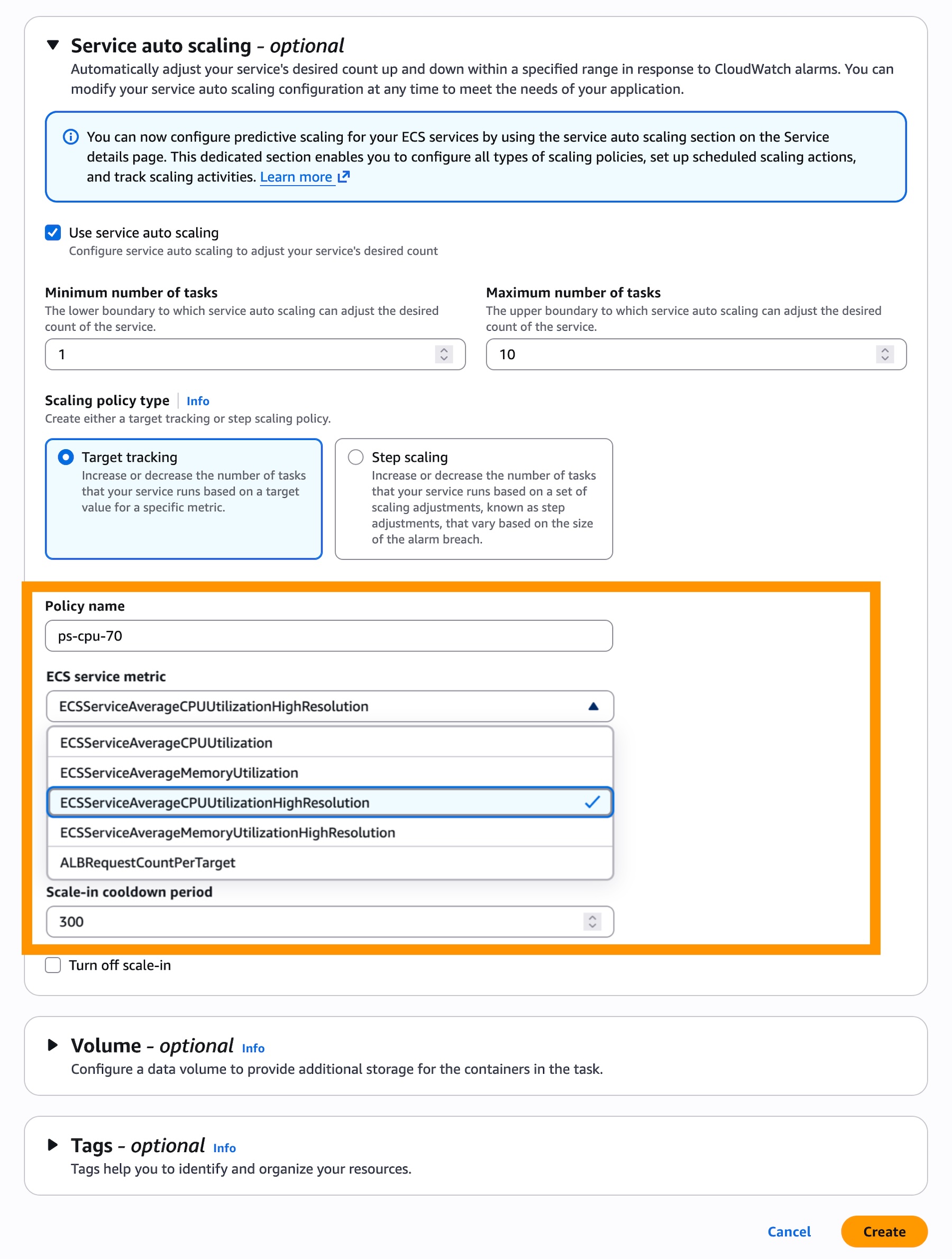
- Under the Service auto scaling tab, select Target Tracking.
- Choose the high-resolution versions of your metrics, specifically
ECSServiceAverageCPUUtilizationHighResolutionorECSServiceAverageMemoryUtilizationHighResolution.
For Existing Services:
- Initiate an "Update Service" action.
- Enable high-resolution metrics in the configuration settings.
- Once the update is deployed, navigate to the "Service and auto scaling" tab.
- Modify the existing scaling policy to utilize the new high-resolution metrics.
Official Perspectives and Considerations
While the performance gains are significant, AWS emphasizes a pragmatic approach to adoption. High-resolution metrics represent a new pricing dimension within Amazon CloudWatch. Because these metrics are generated and processed at a higher frequency, they incur additional costs compared to the standard 60-second metrics, which remain free for ECS.
Architects are advised to evaluate which of their services truly require sub-minute scaling. Mission-critical services with high volatility are the ideal candidates, while static, predictable workloads may not justify the added cost of high-resolution monitoring.
In his commentary on the release, Channy Yun, a leading voice in the AWS developer relations community, noted that the feedback loop from customers was the primary driver for this feature. "We heard from customers who needed their container fleets to adapt faster to rapid, unpredictable demand," Yun stated. By prioritizing the reduction of the scaling lifecycle, AWS has empowered developers to build more resilient systems that are fundamentally better at handling the "unknown unknowns" of modern web traffic.
Conclusion: A New Standard for Container Agility
The launch of high-resolution auto scaling for Amazon ECS marks a pivotal moment in the maturity of cloud-native orchestration. By slashing the time to scale by over 70%, AWS is providing the tools necessary for applications to remain performant in an increasingly high-velocity digital landscape.
For developers and systems architects, the path forward is clear: integrate high-resolution metrics where performance-to-cost ratios align, and leverage the improved responsiveness to build more robust, agile, and cost-effective containerized environments. As we look toward the future of cloud computing, features like this serve as a reminder that the competitive edge in digital services is often found in the millisecond-level efficiencies of the underlying infrastructure.