Amazon Unveils "S3 Annotations": A Paradigm Shift for Data Management and AI Agentic Workflows
In an era where data is the lifeblood of artificial intelligence, the ability to effectively categorize, label, and retrieve information has become a critical bottleneck for enterprises. Today, Amazon Web Services (AWS) announced a significant evolution in its foundational storage service: Amazon S3 Annotations. This new capability allows users to attach rich, large-scale business context directly to objects stored within Amazon Simple Storage Service (S3), effectively bridging the gap between raw data and the intelligent, automated systems that consume it.
As organizations pivot toward building autonomous AI agents and complex, event-driven workflows, the need for metadata that is as dynamic as the data it describes has never been higher. S3 Annotations addresses this by providing a scalable, mutable, and queryable framework that replaces the need for cumbersome, siloed sidecar databases.
Main Facts: What Are S3 Annotations?
At its core, S3 Annotations is a metadata capability designed to scale alongside petabyte-scale storage environments. Unlike traditional object metadata, which is often limited in size and static in nature, Annotations provide a sophisticated layer of contextual information that moves with the data.
Key Technical Specifications
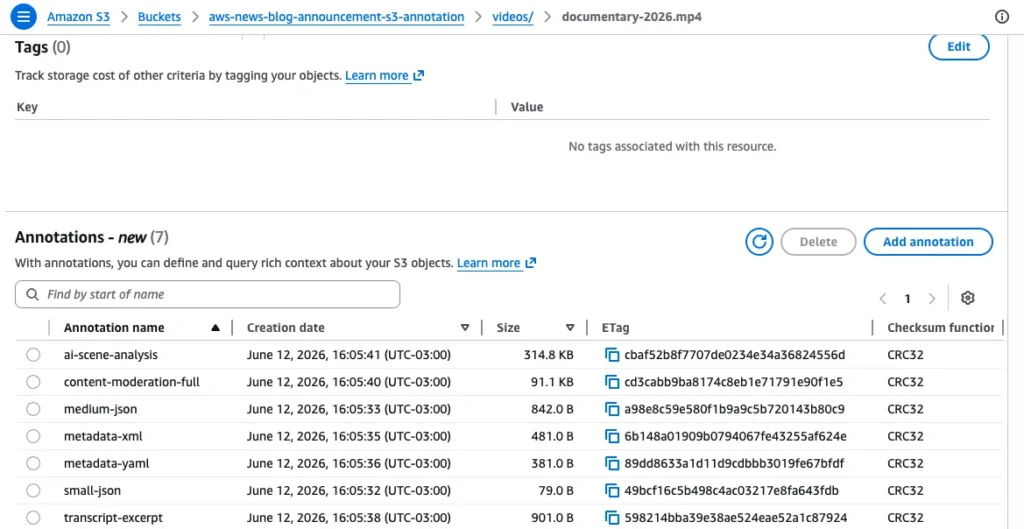
- Capacity: Users can attach up to 1,000 unique named annotations per object.
- Size Constraints: Each individual annotation can be up to 1 MB, with a total capacity of up to 1 GB of metadata per object.
- Flexibility: Annotations support multiple formats, including JSON, XML, YAML, and plain text, allowing for structured and unstructured data storage.
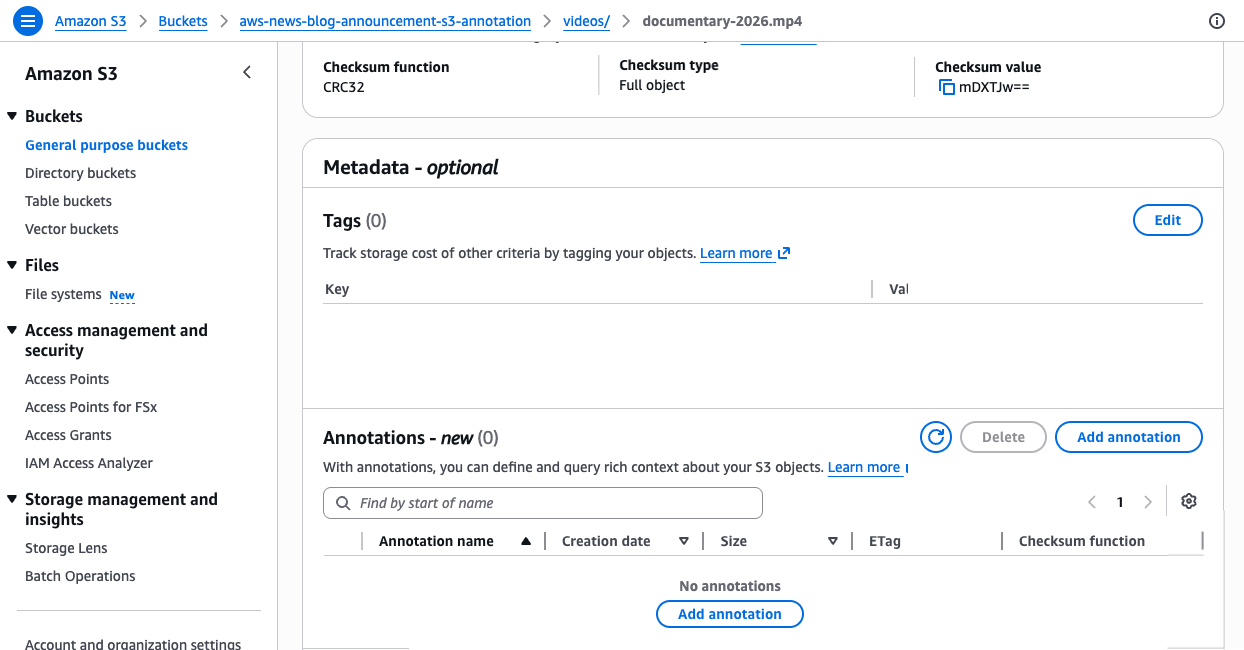
- Mutability: Annotations can be modified or deleted at any time without the need to rewrite or re-upload the parent object, ensuring that context remains current as business requirements evolve.
- Portability: Context travels automatically with the object during copy, replication, or cross-region transfer operations.
By offloading the metadata burden to S3 itself, AWS is enabling developers to move away from maintaining complex external databases that frequently fall out of sync with the underlying storage.
Chronology: The Evolution of Metadata in S3
To understand the significance of this release, one must look at the progression of object storage management within the AWS ecosystem.

- The Era of Fixed Metadata: Initially, S3 relied exclusively on system-defined metadata—properties like storage class, size, and creation timestamps. These were immutable and sufficient for basic infrastructure management.
- The Rise of User-Defined Tags: As cloud adoption grew, AWS introduced user-defined metadata (limited to 2 KB) and Object Tags. While these enabled operational tasks like cost allocation and lifecycle management, they were never intended to hold massive amounts of business intelligence.
- The "Sidecar" Problem: As companies began building data lakes, they resorted to "sidecar" files or separate SQL/NoSQL databases to store context. This created a synchronization nightmare: if an object was moved, deleted, or updated, the sidecar metadata often became orphaned or inaccurate, leading to expensive "data rot."
- The Modern AI Mandate: With the explosion of generative AI, the demand for "agentic" workflows—where AI agents must autonomously discover and process data—created a requirement for metadata that is not only vast but also queryable at scale without triggering expensive data retrieval.
The launch of S3 Annotations marks the culmination of this evolution, providing a native, scalable solution that meets the demands of modern, automated data ecosystems.
Supporting Data: Comparative Analysis
The limitations of previous metadata solutions become apparent when measured against the requirements of modern, high-velocity data pipelines. The table below illustrates how Annotations redefine the storage of business context.
| Capability | Max Size | Mutable? | Best For |
|---|---|---|---|
| System Metadata | Fixed | No | Core object properties (size, class) |
| User Metadata | 2 KB | No | Small, static key-value pairs |
| Object Tags | 10 tags | Yes | Lifecycle management, cost, access |
| Annotations | 1 GB | Yes | Rich business context (AI summaries, tech specs) |
The jump from 2 KB of user-defined metadata to 1 GB of annotations per object represents a 500,000x increase in capacity, effectively enabling developers to store entire machine-readable documents, diagnostic logs, or comprehensive AI-generated summaries directly with the file.
Official Responses and Strategic Implications
Daniel Abib, representing the AWS S3 team, emphasized that the primary motivation for this release is to enable autonomous agentic workflows. "Organizations are building AI agents and autonomous workflows that need to find, understand, and act on data without human intervention," Abib noted in the announcement. By integrating these annotations into fully managed tables, AWS is essentially turning an S3 bucket into a self-describing, searchable database.
The Role of Amazon Athena and Apache Iceberg
The integration with Amazon Athena is arguably the most transformative aspect of this release. When S3 Metadata annotation tables are enabled, S3 automatically indexes the annotations into an Apache Iceberg table. This allows users to perform SQL-based analytics across millions or billions of objects instantly.

For instance, a media company no longer needs to query an external catalog to find all videos with specific frame rates or audio tracks. They can now query the S3 annotation table directly, reducing latency from hours to seconds.
The "Agentic" Future: S3 Tables MCP Server
Perhaps the most forward-looking component is the integration with the S3 Tables Model Context Protocol (MCP) server. This interface allows AI models—such as those running in Amazon SageMaker—to query, discover, and interpret data using natural language. When an agent asks, "Find all PG-rated movies with Spanish subtitles from 2023," it is querying the annotation table directly, effectively treating the object storage as a semantic knowledge base.
Strategic Implications: A New Standard for Data Governance
The implications for industries ranging from media and entertainment to life sciences and finance are profound.
1. Eliminating Synchronization Overhead
In regulated industries, data provenance is critical. Previously, keeping a metadata database aligned with S3 storage required complex "event-driven" architectures—using Lambda functions to watch for S3 events and update the database. With S3 Annotations, the metadata is physically bound to the object. If the object is deleted, the annotation is removed automatically by S3, ensuring compliance and reducing the operational footprint.
2. Streamlining AI Pipelines
AI models require context. By storing AI-generated transcripts or classification labels as annotations, the data "carries its own description." This simplifies the design of data pipelines, as downstream models can read the object and its associated annotations in a single, atomic operation.
3. Cost Efficiency
A major pain point in cloud storage is the cost of querying metadata. By utilizing S3 Metadata tables, customers can query their annotations without restoring archived objects from Glacier or paying for expensive full-object scans. This architectural shift democratizes access to data, allowing even smaller teams to perform large-scale metadata analysis without needing to provision and manage massive database clusters.
Getting Started: Implementation and Workflow
For organizations looking to adopt this capability, the process is straightforward but requires careful planning regarding IAM permissions.
Implementation Steps:
- Grant Permissions: Ensure your IAM policies include
s3:PutObjectAnnotationands3:GetObjectAnnotation. - Attach Annotations: Use the AWS CLI or SDK to attach JSON or text payloads to objects. For example:
aws s3api put-object-annotation --bucket my-media-bucket --key video.mp4 --annotation-name "ai_summary" --annotation-payload ./summary.txt - Enable Annotation Tables: Use the
CreateBucketMetadataConfigurationAPI to enable the automatic indexing of annotations into an Iceberg table. - Query at Scale: Utilize Amazon Athena to perform complex analytics across your bucket, using standard SQL syntax to parse JSON content within the
text_valuecolumn.
Best Practices for Adoption
- Granularity: While 1,000 annotations are permitted, it is best practice to group related metadata (e.g., all technical specs in one JSON annotation, all AI-generated tags in another) to keep the object header clean and manageable.
- Lifecycle Awareness: Remember that while annotations are managed by S3, they incur storage costs at S3 Standard rates. Evaluate the necessity of keeping large annotations for cold-storage objects.
- Security: Leverage the
Roleparameter in theAnnotationTableConfigurationto ensure that only authorized services can read and write sensitive metadata.
Conclusion
The release of S3 Annotations is more than just a feature update; it is a fundamental shift in how the cloud handles the relationship between data and intelligence. By providing a native, high-performance mechanism for attaching rich context to objects, AWS is clearing the path for the next generation of AI-driven applications.
As enterprises continue to struggle with the "data swamp" problem—where data is stored but becomes impossible to categorize or find—S3 Annotations offers a lifeline. By turning passive storage into an active, queryable, and context-aware repository, Amazon S3 is positioning itself not just as a place to keep files, but as the foundational brain of the modern, autonomous enterprise. Whether you are managing petabytes of archival media or feeding real-time data into a fleet of LLM-based agents, this new capability provides the scale, flexibility, and architectural elegance required for the future of cloud computing.