Accelerating Generative AI: AWS Unveils Amazon Bedrock Managed Knowledge Base
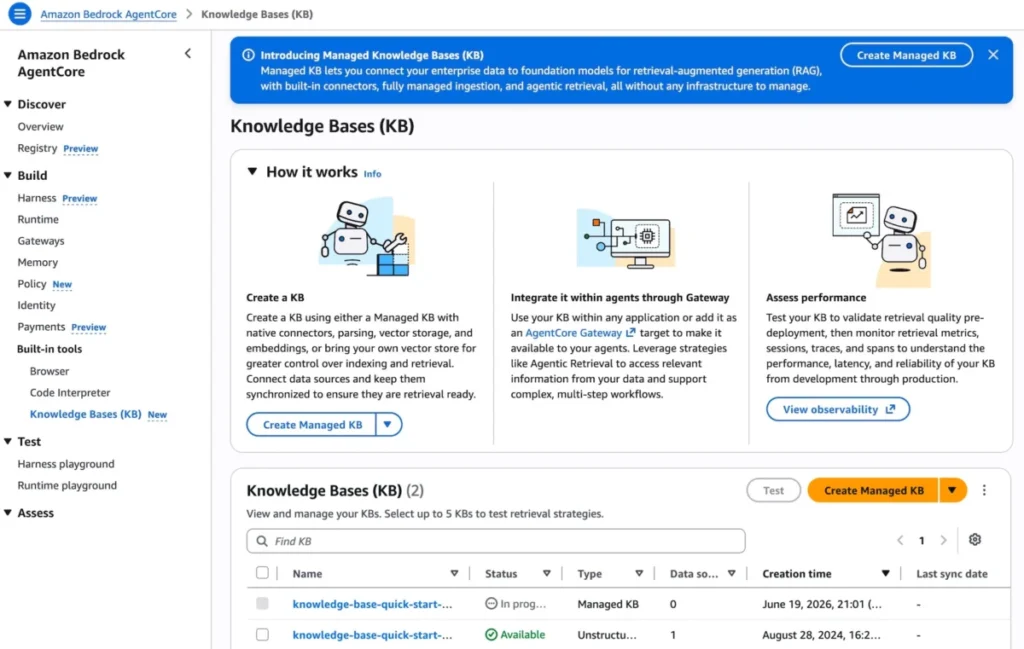
In a significant move to streamline the deployment of enterprise-grade artificial intelligence, Amazon Web Services (AWS) has announced the launch of Amazon Bedrock Managed Knowledge Base. This new suite of capabilities is designed to eliminate the heavy lifting associated with building Retrieval-Augmented Generation (RAG) pipelines, allowing developers to connect their proprietary enterprise data to foundation models in minutes rather than weeks.
As organizations race to integrate generative AI into their operational workflows, the challenge of maintaining secure, reliable, and context-aware data pipelines has become a primary bottleneck. By abstracting the complex infrastructure required for RAG—such as storage, embedding management, re-ranking, and retrieval orchestration—AWS is positioning Managed Knowledge Base as the foundational layer for the next generation of agentic AI applications.
The Core Challenge: Why RAG Remains Complex
Building an effective RAG system is rarely as simple as connecting a database to a Large Language Model (LLM). Developers typically grapple with three persistent challenges that stall production-grade deployments:

- Infrastructure Fragmentation: Integrating storage solutions, vector databases, embedding models, and re-rankers requires extensive "undifferentiated heavy lifting." Maintaining these disparate components often distracts engineering teams from focusing on the actual business application.
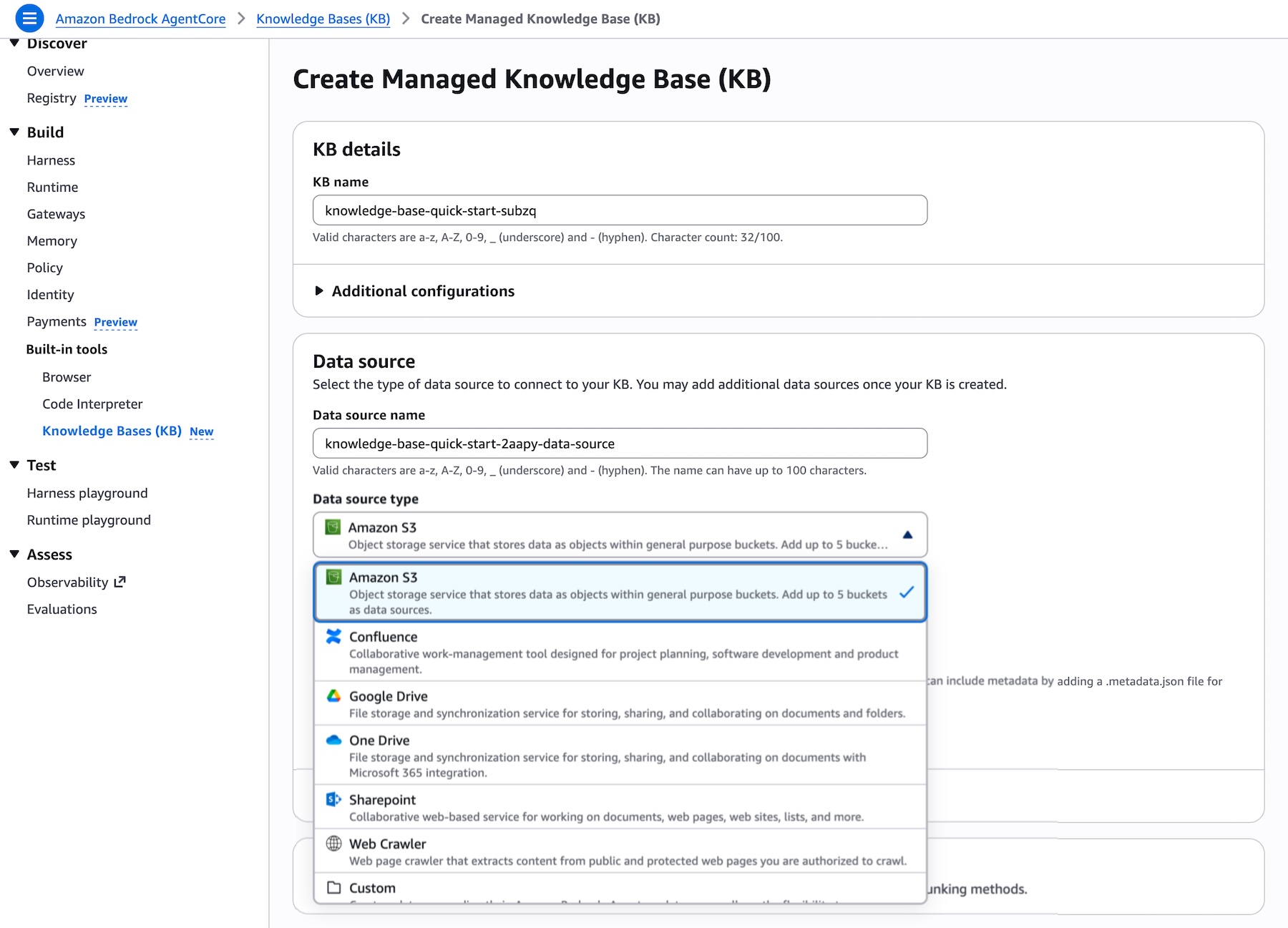
- Data Ingestion and Parsing: Enterprise data exists in a messy, heterogeneous state across platforms like SharePoint, Google Drive, and Confluence. Preparing this data for accurate semantic search requires significant preprocessing, often involving custom-built scripts that are difficult to scale.
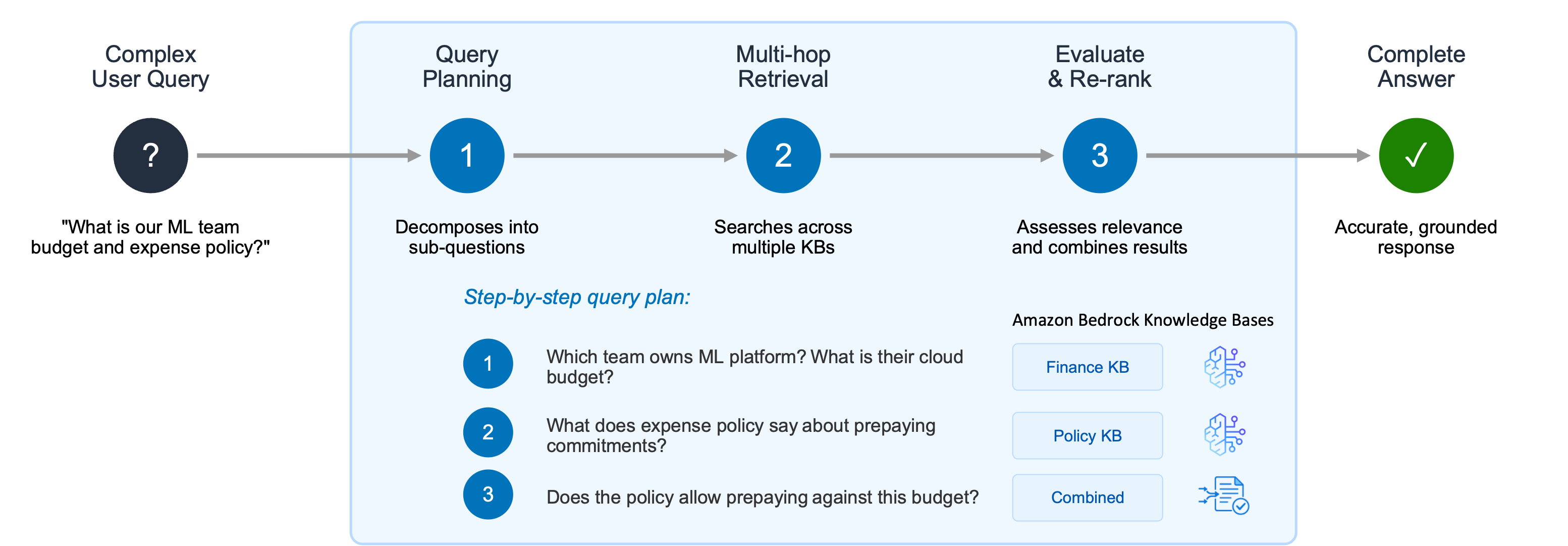
- Complex Reasoning Gaps: Traditional RAG systems often fail on multi-hop queries. If a user asks a question that requires correlating information from multiple documents or departments, standard retrieval methods frequently fall short, leading to incomplete or inaccurate AI responses.
Amazon Bedrock Managed Knowledge Base addresses these hurdles by consolidating these fragmented workflows into a single, cohesive, and managed primitive.
A Chronology of the Development
The path to Managed Knowledge Base follows a clear trajectory of AWS’s commitment to making generative AI accessible to the enterprise:
- Initial Bedrock Launch: AWS introduced Amazon Bedrock to provide a serverless way to build generative AI applications using foundation models from leading providers.
- The Rise of RAG: As customers began experimenting with Bedrock, the demand for better data grounding led to the introduction of Knowledge Bases for Amazon Bedrock, which provided a vector store and retrieval mechanism.
- The Agentic Shift: As users shifted from simple chat interfaces to complex, autonomous agents, the need for advanced reasoning and multi-step orchestration became clear.
- June 2026 – The Managed Evolution: AWS launches the "Managed Knowledge Base," shifting the paradigm from a manual integration of vector databases to a fully automated, end-to-end pipeline that handles ingestion, parsing, and reasoning automatically.
Technical Innovations: Under the Hood
The new service introduces several "smart" features that automate the lifecycle of data retrieval.

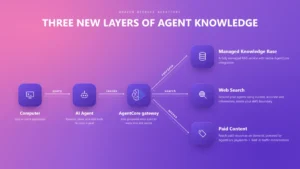
Smart Parsing for Data Ingestion
One of the most labor-intensive aspects of RAG is data preparation. The new Smart Parsing feature eliminates the need for manual configuration. By pointing the system at a data source—whether it be an Amazon S3 bucket, a SharePoint site, or a web crawler—the service automatically determines the optimal parsing strategy for that specific file type. It combines layout analysis, table extraction, and semantic chunking to ensure that the retrieved data is high-fidelity and contextually relevant.
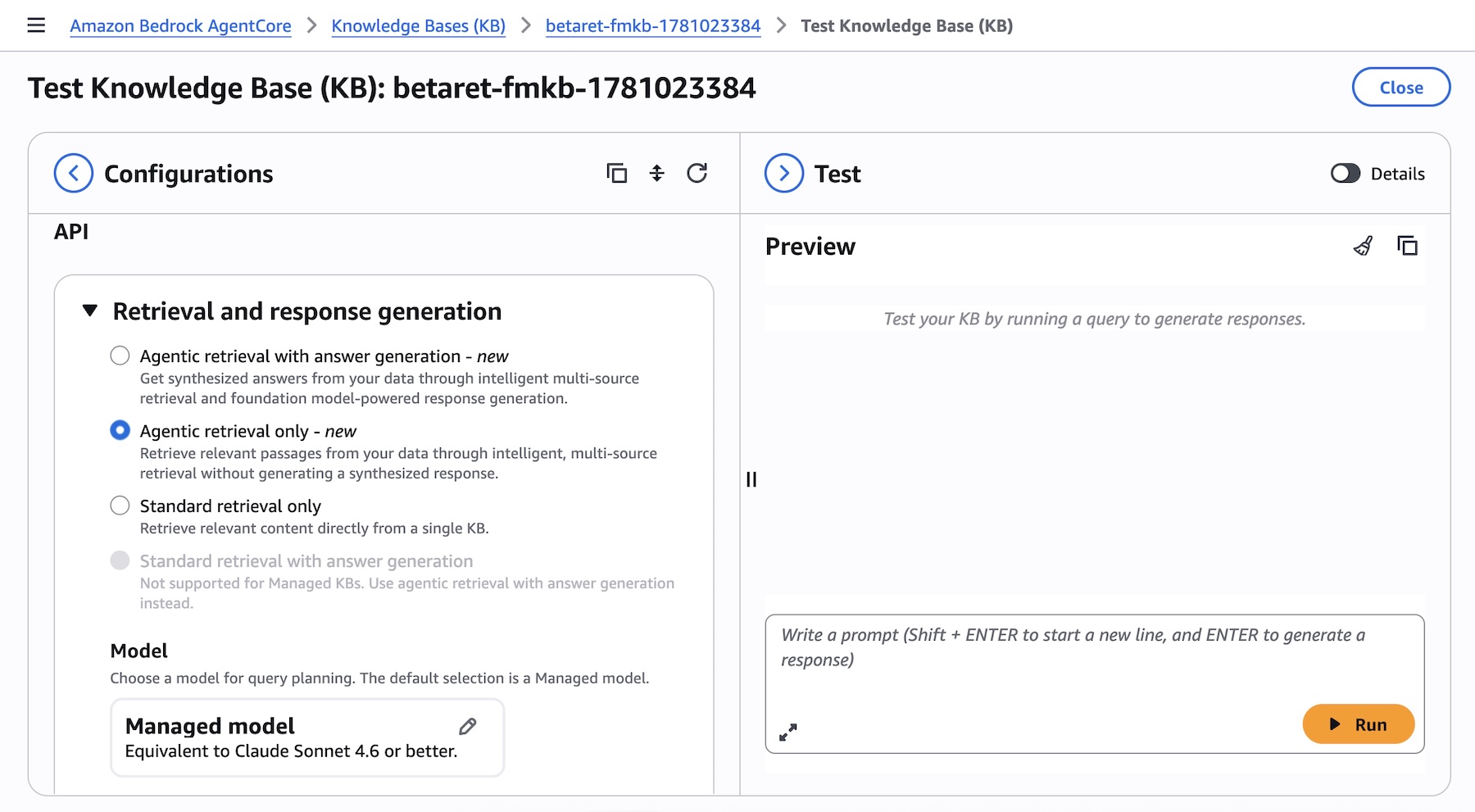
The Agentic Retriever
Perhaps the most transformative addition is the Agentic Retriever. This feature is built to handle complex, multi-step queries that require reasoning. When a user submits a query that cannot be answered by a single document, the Agentic Retriever breaks the question down into a logical plan. It performs multi-hop retrieval across various knowledge sources, evaluates intermediate findings, and synthesizes a final, grounded answer. This mimics the human process of research, moving beyond simple keyword or vector similarity.
Seamless Integration via AgentCore
For developers working within the broader AWS ecosystem, Managed Knowledge Base integrates natively with Amazon Bedrock AgentCore. This integration provides:
- Built-in Observability: Developers can monitor performance metrics directly from the AgentCore dashboard.
- Role-Based Access Control: IAM roles are auto-generated and managed, ensuring that enterprise data remains secure and compliant.
- Model Context Protocol (MCP) Support: By exposing the knowledge base as an MCP server, AWS ensures compatibility with a vast range of open-source frameworks, including LangChain, CrewAI, LlamaIndex, and LangGraph.
Supporting Data: Efficiency and Performance
The primary value proposition of this new offering is the dramatic reduction in time-to-market. According to internal AWS documentation, the transition from raw enterprise data to a production-ready, agent-compatible knowledge base has been reduced from several weeks of custom engineering to a "few clicks" within the Bedrock console.
Furthermore, the flexibility of the service is underscored by its model-agnostic architecture. While the system provides a robust set of default embedding and re-ranking models for those who want to get started quickly, it does not force vendor lock-in. Developers retain the freedom to swap out underlying foundation models as new, more efficient, or specialized models emerge, protecting the organization’s long-term investment.
Official Perspectives and Implications
"Organizations building agentic AI applications need secure, reliable, and up-to-date access to enterprise-wide data," noted Daniel Abib, a key voice in the AWS product development team. By abstracting the infrastructure layer, AWS is effectively democratizing access to high-end RAG capabilities.
The Implications for Developers
For the developer community, this represents a shift in focus. Instead of spending hours tuning vector similarity thresholds or optimizing chunking strategies, engineers can focus on:
- Business Logic: Refining the prompts and guardrails that dictate how an agent interacts with the end user.
- User Experience: Designing more intuitive conversational flows.
- Evaluation: Using the built-in observability metrics to continuously improve the accuracy and relevance of the AI’s responses.
The Implications for the Enterprise
For enterprises, the implications are equally profound. The barrier to entry for building proprietary, internal-facing AI agents has been lowered. Companies that were previously hesitant to deploy AI due to the complexity of data security and infrastructure maintenance now have a pathway to create "knowledge-aware" agents that are grounded in their own corporate policy, budget documentation, and historical research.
Getting Started: Availability and Pricing
Amazon Bedrock Managed Knowledge Base is available immediately across several major global regions, including US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney, Tokyo), and Europe (Dublin, Frankfurt, London).
The pricing model follows the standard AWS philosophy of "pay-for-what-you-use," with no upfront commitments. Costs are calculated based on two primary metrics:
- Indexed Data Storage: The volume of data stored in the knowledge base.
- Retrieval Volume: The number of on-demand retrievals performed during user interactions.
For those looking to explore the capabilities without immediate cost, the service is included in the AWS Free Tier, allowing new customers to experiment with RAG pipelines in a sandbox environment.
Conclusion
The release of Amazon Bedrock Managed Knowledge Base marks a pivotal moment in the maturity of generative AI. By turning the complex, error-prone, and labor-intensive process of RAG pipeline construction into a managed service, AWS is setting a new standard for enterprise AI development. Whether an organization is using LangChain, LlamaIndex, or native AWS services, the ability to rapidly turn siloed corporate data into an intelligent, queryable asset is no longer a luxury for tech giants—it is now a standard, accessible tool for every developer.
As the ecosystem continues to evolve, the combination of Smart Parsing, Agentic Retrieval, and MCP compliance ensures that AWS remains at the center of the generative AI revolution, providing the scaffolding upon which the next generation of autonomous business agents will be built.