Bridging the Data Gap: AWS Unveils Amazon S3 Annotations to Revolutionize Object Metadata
In an era where data is the lifeblood of artificial intelligence, the ability to effectively catalog, index, and retrieve information has become a primary bottleneck for enterprise innovation. Today, Amazon Web Services (AWS) addressed this challenge head-on by announcing a transformative new capability for Amazon Simple Storage Service (S3): S3 Annotations. This feature allows organizations to attach rich, large-scale business context—ranging from AI-generated summaries to complex technical specifications—directly to their S3 objects, effectively collapsing the distance between raw data and the intelligence needed to act upon it.
The Core Innovation: Moving Beyond Metadata Limitations
For years, developers and data architects have struggled with the limitations of traditional metadata. System-defined metadata, object tags, and small user-defined headers served their purpose for basic lifecycle management, but they were never designed for the era of Large Language Models (LLMs) and autonomous agents.
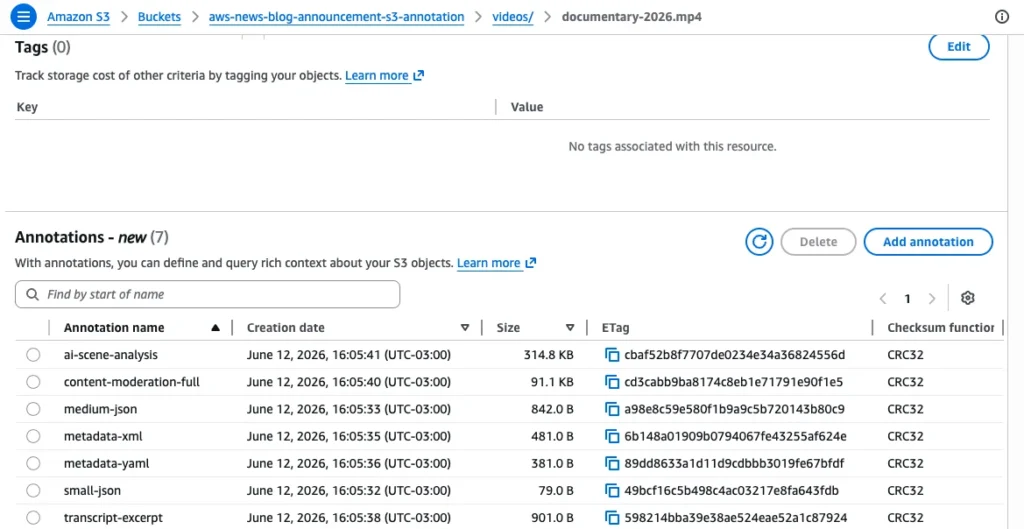
With the introduction of S3 Annotations, AWS is enabling users to store up to 1,000 named annotations per object, with each annotation supporting up to 1 MB in size. This results in a staggering potential of 1 GB of metadata per object. Crucially, these annotations are mutable—they can be updated, deleted, or appended without the need to rewrite the underlying object. This flexibility allows metadata to evolve alongside the data itself, ensuring that as a file’s context changes, its descriptive information remains current.
A New Standard for Scalability
Unlike previous methods, which often forced organizations to build and maintain "sidecar" databases or external cataloging systems, S3 Annotations reside natively within the storage layer. This architecture ensures that when an object is copied, replicated, or moved across regions, the associated business context travels with it. When an object is deleted, its annotations are automatically purged, eliminating the risk of "metadata rot" and reducing the administrative overhead associated with managing orphaned data in external systems.
Chronology of Metadata Evolution: From Headers to Intelligence
The journey toward S3 Annotations represents the final step in a multi-decade evolution of cloud storage management.

- The Early Days (2006–2015): In the early years of S3, metadata was limited to basic system attributes like object size, storage class, and standard HTTP headers. Metadata was primarily a way for the system to understand the object, not for the user to understand the content within the object.
- The Rise of Tags (2015–2020): AWS introduced Object Tags, which allowed for cost allocation, access control, and basic lifecycle policies. While revolutionary for operations, they were limited to 10 tags per object, insufficient for descriptive AI-driven workflows.
- The External Catalog Era (2020–2025): As organizations began building data lakes, they turned to external databases (like Amazon DynamoDB or RDS) to store "sidecar" metadata. This created a high-latency, high-cost maintenance cycle, requiring developers to synchronize two different systems constantly.
- The Era of Native Intelligence (2026–Present): With the launch of S3 Annotations, the industry shifts toward "Self-Describing Data." By integrating metadata directly into the S3 storage engine, AWS has effectively moved the intelligence into the data plane itself.
Supporting Data: Why Annotations Matter
To understand the significance of this update, one must look at the comparative capabilities of S3’s current metadata offerings. The following table illustrates why annotations are a paradigm shift for data engineers:
| Capability | Max Size | Mutable? | Best For |
|---|---|---|---|
| System Metadata | Fixed | No | Basic object properties |
| User Metadata | 2 KB | No | Small, static key-value pairs |
| Object Tags | 10 tags | Yes | Access control & lifecycle |
| S3 Annotations | 1 GB | Yes | Rich business/AI context |
The jump from 2 KB of user-defined headers to 1 GB of structured, queryable data (JSON, XML, YAML) is not merely an incremental improvement; it is a fundamental expansion of what a cloud object can "know" about itself.
Implications for AI and Autonomous Workflows
The most profound impact of S3 Annotations will be felt in the development of AI agents. Modern AI systems require massive amounts of context to make informed decisions. Traditionally, an AI agent might need to retrieve an object, parse its content, and then cross-reference a separate database to understand its provenance or technical details. This process is expensive, slow, and compute-intensive.
The Role of Amazon Athena and Apache Iceberg
By enabling S3 Metadata annotation tables, AWS has ensured that this rich context is immediately queryable via Amazon Athena. Because these tables are built on the open-source Apache Iceberg format, they offer near-instant performance.
When an organization enables annotation tables, S3 automatically indexes the annotations into a fully managed table. An AI agent, using the new S3 Tables MCP (Model Context Protocol) server, can now perform natural language queries against this metadata. For example, a researcher could ask an agent to "Find all videos from 2024 with a resolution of 4K that include a specific actor." The agent performs a SQL-like query on the annotation table—without needing to open or download a single video file—resulting in sub-second discovery.

Streamlining Media and Compliance
For media companies, the ability to attach technical specs (like frame rate, codec, and audio tracks) alongside AI-generated narrative summaries allows for a "searchable archive" that is always up-to-date. In the compliance sector, organizations can store legal hold information, audit logs, or PII (Personally Identifiable Information) classification tags directly on the object. This ensures that even if data is moved between buckets or accounts, the compliance markers remain anchored to the file.
Technical Implementation: A Developer’s Perspective
The implementation of S3 Annotations is designed to be developer-friendly, utilizing the existing s3api command set. Integrating this into existing CI/CD pipelines requires minimal refactoring.
Example: Enriching Media Assets
Using the AWS CLI, developers can now attach rich metadata with simple commands:
# Attaching a JSON technical specification
aws s3api put-object-annotation
--bucket my-media-bucket
--key videos/production_final.mp4
--annotation-name "tech_specs"
--annotation-payload ./specs.jsonThis command structure allows teams to use multiple, independent annotations for the same file. One team might handle "technical metadata," while another handles "legal clearance," and a third handles "AI-generated content ratings." Because each annotation is named and separate, teams can update their specific domain of data without causing versioning conflicts for other stakeholders.
Official Responses and Industry Outlook
In the lead-up to the launch, AWS engineers highlighted that the primary driver for this feature was customer feedback regarding the "complexity tax." Organizations were spending more on managing metadata synchronization than on the storage itself.
"Our goal with S3 Annotations is to remove the friction of data discovery," says Daniel Abib, a lead architect at AWS. "By allowing customers to store rich context directly in S3, we are enabling a future where data is not just stored, but understood by the infrastructure itself. We are effectively turning static storage buckets into active, intelligent knowledge bases."
Industry analysts are already signaling that this will be a mandatory requirement for any enterprise-grade data lake moving forward. The ability to query across petabytes of data—without the need to "rehydrate" archived objects or pay for egress from a separate database—is a significant cost-saving lever for large-scale operations.
The Future of "Active" Storage
The introduction of S3 Annotations is a clear signal that the future of cloud storage is "active." By embedding metadata into the storage layer, AWS is preparing for a world where AI agents are the primary users of the cloud.
As we look toward the remainder of 2026, the adoption of these tools will likely accelerate, particularly in highly regulated industries and media production houses. The ability to move from "searching for a file" to "querying the context of an asset" represents a generational shift in how we interact with the digital world.
For organizations looking to get started, the integration path is clear: enable annotation tables, define your schema, and begin the process of enriching your data lake. With the power of S3 Annotations, your objects are no longer just files—they are intelligent assets, ready to be discovered, analyzed, and utilized at the speed of thought.