Beyond the Final Output: A Comprehensive Framework for Rigorous AI Agent Evaluation

In the rapidly evolving landscape of artificial intelligence, the transition from static Large Language Models (LLMs) to dynamic, autonomous AI agents represents a fundamental shift in software engineering. However, many development teams are inadvertently stalling their progress by applying "legacy" evaluation techniques. They run a few tasks, inspect the final output, and assume the system is robust.
This superficial approach is a recipe for failure. An AI agent is not merely a generator of text; it is a complex, multi-step decision engine. If an agent selects an inappropriate tool or generates malformed arguments, the system may fail silently or produce a hallucinated result. Relying on end-to-end output evaluation is like checking if a car arrived at its destination without ever checking the engine, the transmission, or the fuel levels.
To build reliable agents, we must pivot toward a rigorous evaluation framework that examines the entire execution process.
Main Facts: The Anatomy of Agent Failure
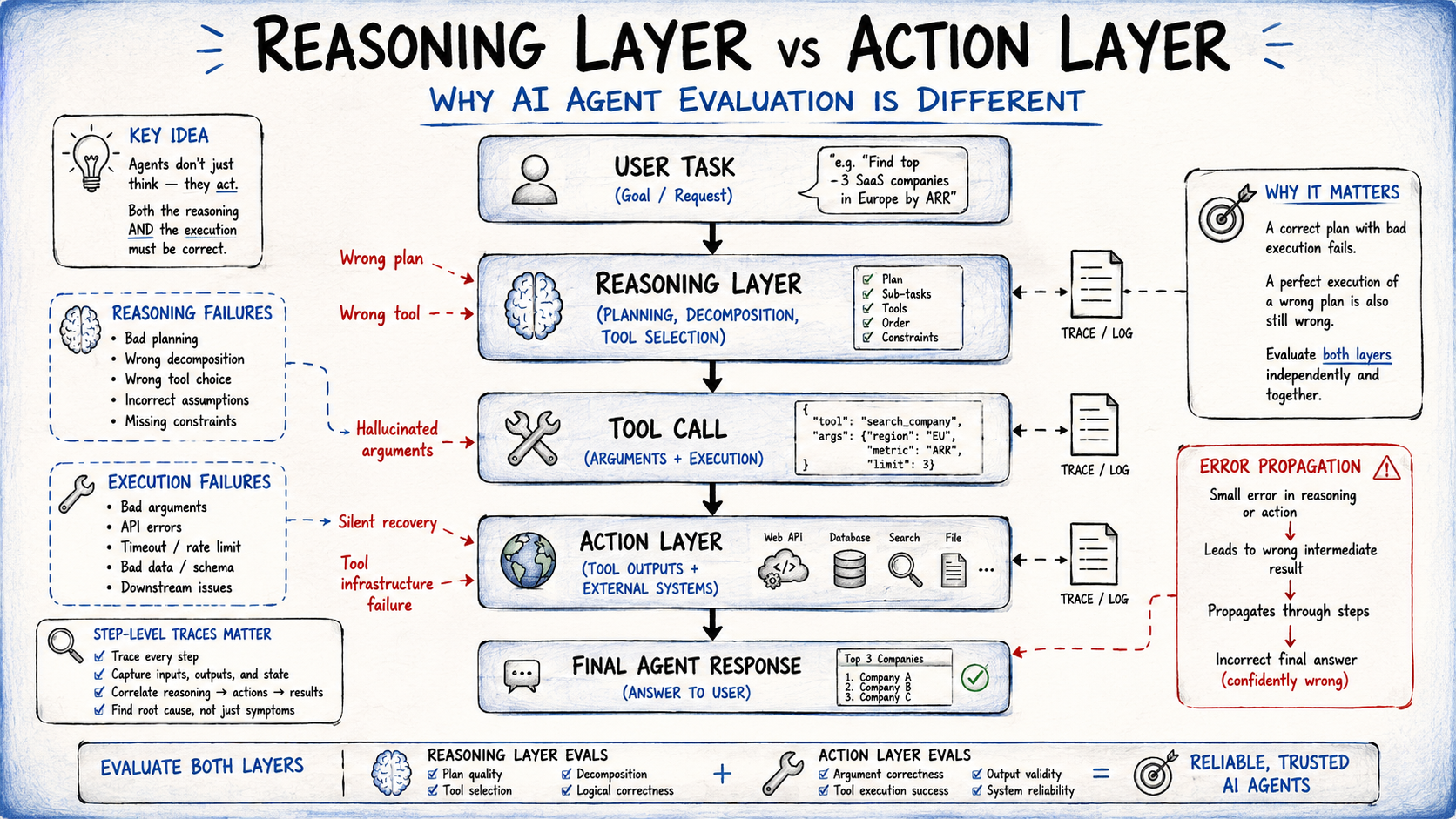
The primary challenge in evaluating AI agents is that they operate across multiple failure surfaces. Unlike a standard LLM, which takes an input and produces an output, an agent engages in an iterative loop of reasoning, tool selection, argument generation, and execution.
The Reasoning vs. Action Dichotomy
Evaluation must be bifurcated to account for the two distinct layers of agent operation:
- The Reasoning Layer: This governs the agent’s internal logic. Did the model identify the correct objective? Did it choose the most efficient path to solve the problem?
- The Action Layer: This governs the physical interface with tools. Did the agent format the API call correctly? Did it handle the tool’s error message gracefully?
Treating these as a single unit of measurement hides the "why" behind failures. If an agent fails a task, was it because it didn’t know how to solve it, or because it couldn’t execute the steps required? Without granular, step-level traces—logs that capture every intermediate state—debugging becomes an exercise in guesswork.

Chronology: A Roadmap to Systematic Evaluation
Building an evaluation harness is not a one-time task; it is a lifecycle process that must be integrated into the CI/CD pipeline.
Phase 1: Defining Success Criteria
Before writing a single line of test code, teams must define what "success" looks like. A high-quality evaluation task is one where two independent domain experts would arrive at the same pass/fail verdict. This requires:
- Unambiguous Task Specifications: Clear definitions of the agent’s goal.
- Reference Solutions: Known-correct outputs that provide a "gold standard" for comparison.
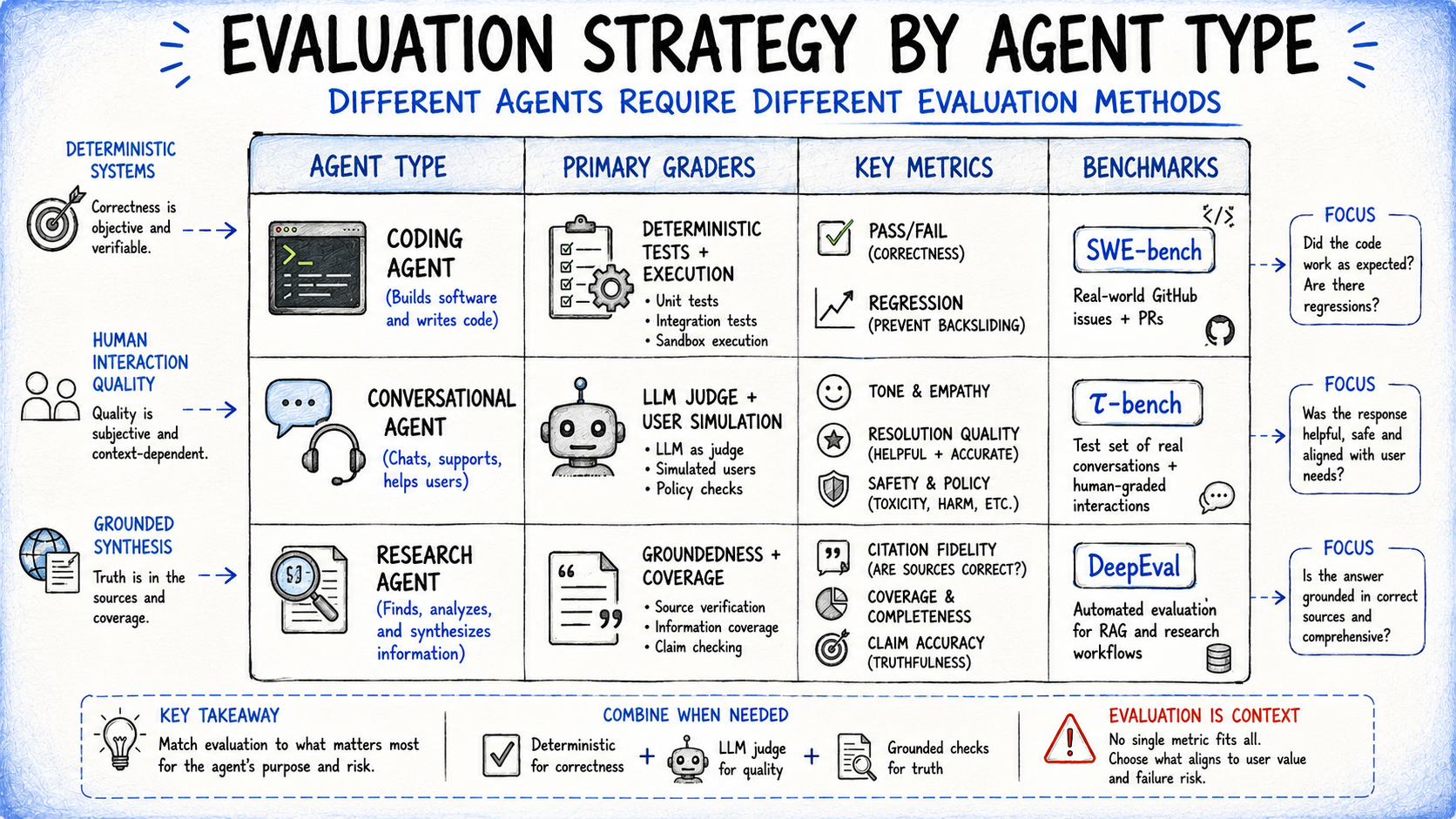
Phase 2: Implementing Deterministic Graders
For the Action Layer, developers should leverage code-based, deterministic graders. These are fast, objective, and highly reproducible. They check for specific conditions—such as whether a tool was called with the correct JSON schema, whether a status code was returned, or if specific required fields exist in the response.
Phase 3: Deploying Model-Based Judges
For the Reasoning Layer, where the nuance of tone, faithfulness to context, and empathy are involved, code-based graders fall short. This is where "LLM-as-a-Judge" becomes essential. By utilizing a stronger model to evaluate the output of the agent, developers can handle open-ended complexity. To ensure these judges remain reliable, teams must:
- Write Structured Rubrics: Avoid vague instructions like "be helpful." Instead, break the rubric down into discrete, measurable components.
- Calibrate Against Human Judgment: Periodically compare the judge’s output against human-graded samples to ensure there is no drift in the model’s evaluation logic.
Supporting Data: Managing Non-Determinism
One of the most persistent hurdles in agent evaluation is non-determinism. Because agents are stochastic, the same input can result in different execution paths. A single-trial evaluation is, therefore, statistically insignificant.
The Metrics of Reliability
To capture this variance, engineers are increasingly moving toward distribution-based metrics:
- pass@k: This measures the probability that at least one of k attempts will succeed. This is useful when the agent only needs to get it right once to satisfy the user.
- pass^k: This is a more stringent metric, measuring the probability that all k attempts succeed. This is critical for agents performing sensitive tasks, such as financial transactions or data deletion, where consistent reliability is non-negotiable.
Data shows that even a high-performing agent with a 75% single-trial success rate will see its reliability plummet when subjected to the pass^k standard. Recognizing this difference is a product decision that dictates the safety and utility of the agent.
Official Perspectives: Capability vs. Regression
Industry leaders, including teams at Anthropic and Google, distinguish between two types of evaluation suites that serve different stages of the development lifecycle.
Capability Evals (The "Frontier")
These tests are designed to measure the agent’s potential. They should be difficult, with relatively low initial pass rates. Their goal is to identify if the agent can handle new, complex scenarios. Once a capability eval reaches a 90% pass rate, it has effectively "saturated"—it is no longer testing potential, but rather verifying stability.
Regression Evals (The "Guardrails")
These tests are the safety net. They consist of previously solved tasks that the agent must continue to pass at near 100%. When a regression test fails, it is a high-priority alert that a recent update has broken existing functionality.
The Strategy: As capability evals saturate, they should be transitioned into the regression suite. However, teams must be careful: if they wait too long to introduce new, challenging evaluations, the agent may appear to be performing perfectly while actually stagnating in its intelligence.
Implications: From Development to Production
The ultimate test for any AI agent is not the sandbox, but the wild. Production monitoring is the final, and perhaps most important, layer of the evaluation stack.
The Holistic Evaluation Matrix
A truly robust system requires a combination of signals:
- Automated Evals: Essential for rapid, high-frequency feedback during the development cycle.
- Production Monitoring: Tracking real-world latency, error rates, and token usage to catch edge cases that synthetic tests never encountered.
- User Feedback: The most honest, albeit sparse, signal of whether an agent is actually solving human problems.
- Manual Transcript Review: A critical qualitative layer. By periodically reading logs of how the agent reasoned through a task, developers gain intuition that no automated metric can provide.
Building the Infrastructure
The industry is coalescing around specialized tooling to facilitate this. Frameworks like LangSmith, Arize Phoenix, Braintrust, and Langfuse have become the industry standard for tracing, while DeepEval and Harbor provide the harness layers necessary to automate the evaluation loop.
Conclusion
The era of "set it and forget it" AI is over. To move agents from experimental prototypes to production-grade systems, developers must treat evaluation as a first-class citizen of the software development lifecycle. By focusing on step-level traces, separating reasoning from action, and rigorously accounting for non-determinism, teams can transform their agents from unpredictable black boxes into reliable, high-performing partners.
As we look toward the future, the ability to measure—and therefore improve—agent behavior will be the defining competitive advantage in the AI space. The roadmap is clear: start with unambiguous specifications, build a multi-layered testing strategy, and never stop monitoring the gap between your synthetic evals and the reality of user interaction.