AWS Turbocharges Container Agility: Amazon ECS Service Auto Scaling Now 4x Faster with High-Resolution Metrics
In the high-stakes world of cloud-native computing, the difference between a seamless user experience and a service outage often comes down to seconds. Amazon Web Services (AWS) has long provided developers with robust tools to manage containerized workloads through Amazon Elastic Container Service (ECS). Today, the cloud giant announced a significant evolution in its operational capabilities: the introduction of high-resolution, 20-second metrics for ECS service auto scaling.
This upgrade is designed to eliminate the "latency gap" that occurs when traffic spikes outpace the reactive capabilities of an infrastructure. By shifting from standard 60-second intervals to high-resolution 20-second cycles, AWS is empowering businesses to scale their infrastructure with unprecedented speed, ensuring that application performance remains stable even during the most volatile traffic surges.
The Core Innovation: Shrinking the Feedback Loop
At its heart, auto scaling is a reactive process. It requires a system to observe a change in demand (metrics), analyze that change against predefined thresholds (policy), and execute a change in the environment (task provisioning). Historically, this process was constrained by the frequency of metric collection.
By enabling 20-second resolution metrics, Amazon ECS is essentially shortening the "heartbeat" of the monitoring system. The result is a dramatic improvement in response time. According to internal AWS benchmarking tests, the time required to trigger a scale-out operation has been slashed from 363 seconds to just 86 seconds—a 76% improvement. Perhaps more importantly for engineers, the total time to scale and provision new tasks has plummeted from 386 seconds to 109 seconds, representing a 3.5x increase in overall operational velocity.
A Chronology of Scaling Evolution on AWS
To understand the magnitude of this update, it is helpful to look back at the trajectory of AWS container management.
The Early Days: Static Provisioning
In the nascent stages of cloud adoption, scaling was largely a manual or scheduled affair. Developers would provision "enough" capacity to handle peak loads, leading to massive inefficiencies during off-peak hours.
The Rise of Target Tracking (2017–2020)
AWS introduced Target Tracking scaling policies, which allowed services to scale dynamically based on real-time utilization. This moved the industry toward "reactive" scaling—where the system reacts to CPU or memory pressure. While highly effective, it was bounded by the standard one-minute CloudWatch polling interval, which sometimes proved too slow for "flash crowd" scenarios.
The Predictive Era (2020–2023)
Recognizing that some traffic patterns are cyclical (e.g., e-commerce sales, morning login spikes), AWS integrated machine learning-based predictive scaling. This allowed ECS to anticipate demand based on historical patterns, effectively "pre-warming" infrastructure.
The High-Resolution Milestone (2024–Present)
The current launch represents the convergence of reactive and predictive efficiency. By enabling high-resolution metrics, AWS has bridged the gap for unpredictable traffic spikes that fall outside the bounds of historical patterns, effectively giving users a "real-time" scaling engine that operates at the speed of modern web traffic.
Supporting Data: The 3.5x Performance Multiplier
The data provided by AWS engineering teams highlights the tangible benefits of this transition. The following table summarizes the reduction in latency during high-load scenarios:

| Metric | Previous (60s) | New (20s) | Improvement |
|---|---|---|---|
| Trigger Scale-Out | 363 Seconds | 86 Seconds | 4.2x Faster |
| Total Provisioning | 386 Seconds | 109 Seconds | 3.5x Faster |
These numbers are not merely statistical curiosities; they represent the difference between a user experiencing a "503 Service Unavailable" error and a smooth browsing experience during a viral marketing event or a sudden surge in API requests.
Implementation: How Engineers Can Leverage the Update
For DevOps engineers and systems architects, implementing these changes is straightforward, though it requires a configuration shift.
Enabling the Feature
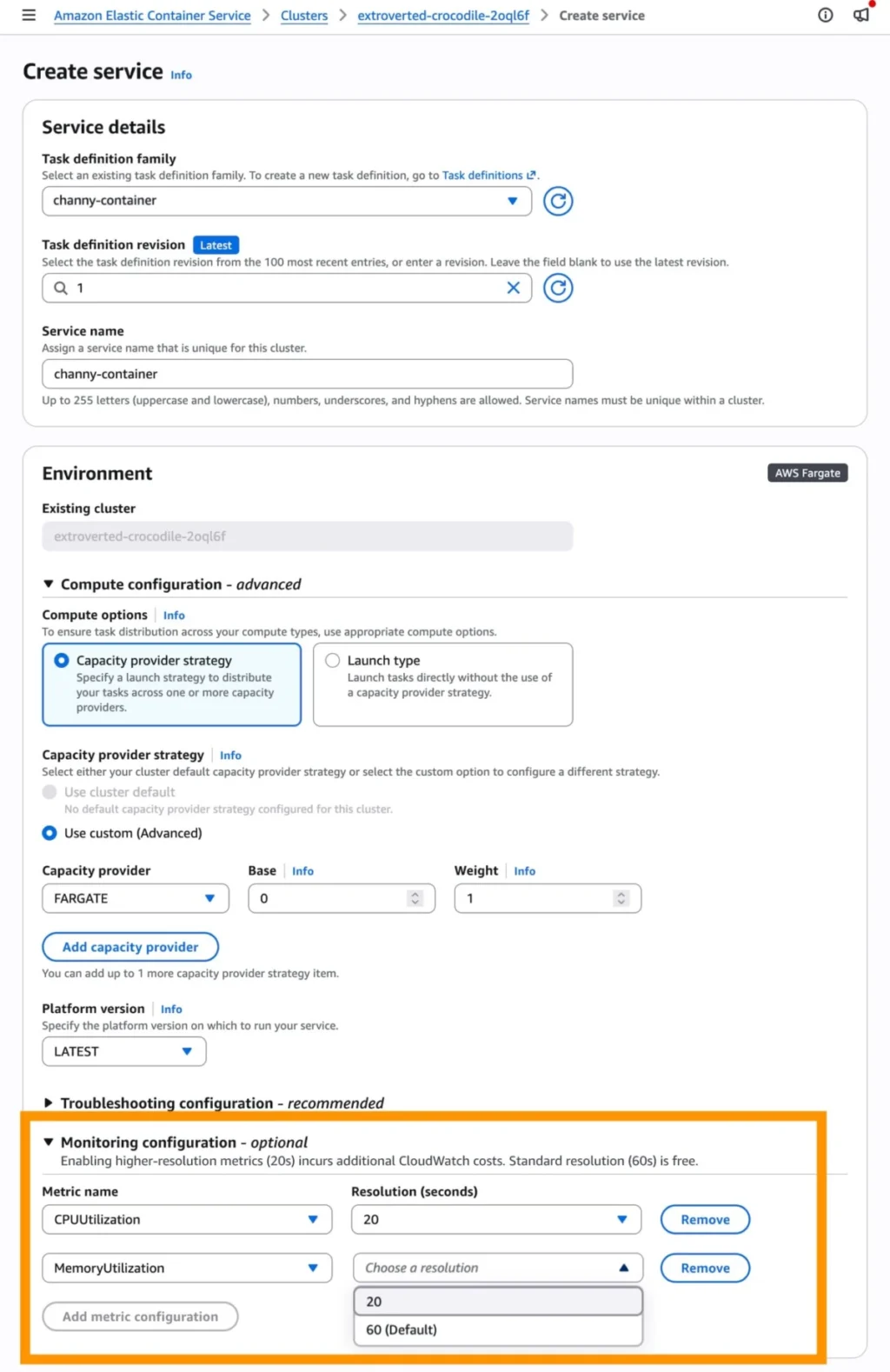
The update is available across all primary ECS compute options: AWS Fargate, ECS Managed Instances, and standard Amazon EC2 instances. Users can enable the feature either during service creation or by updating an existing service.
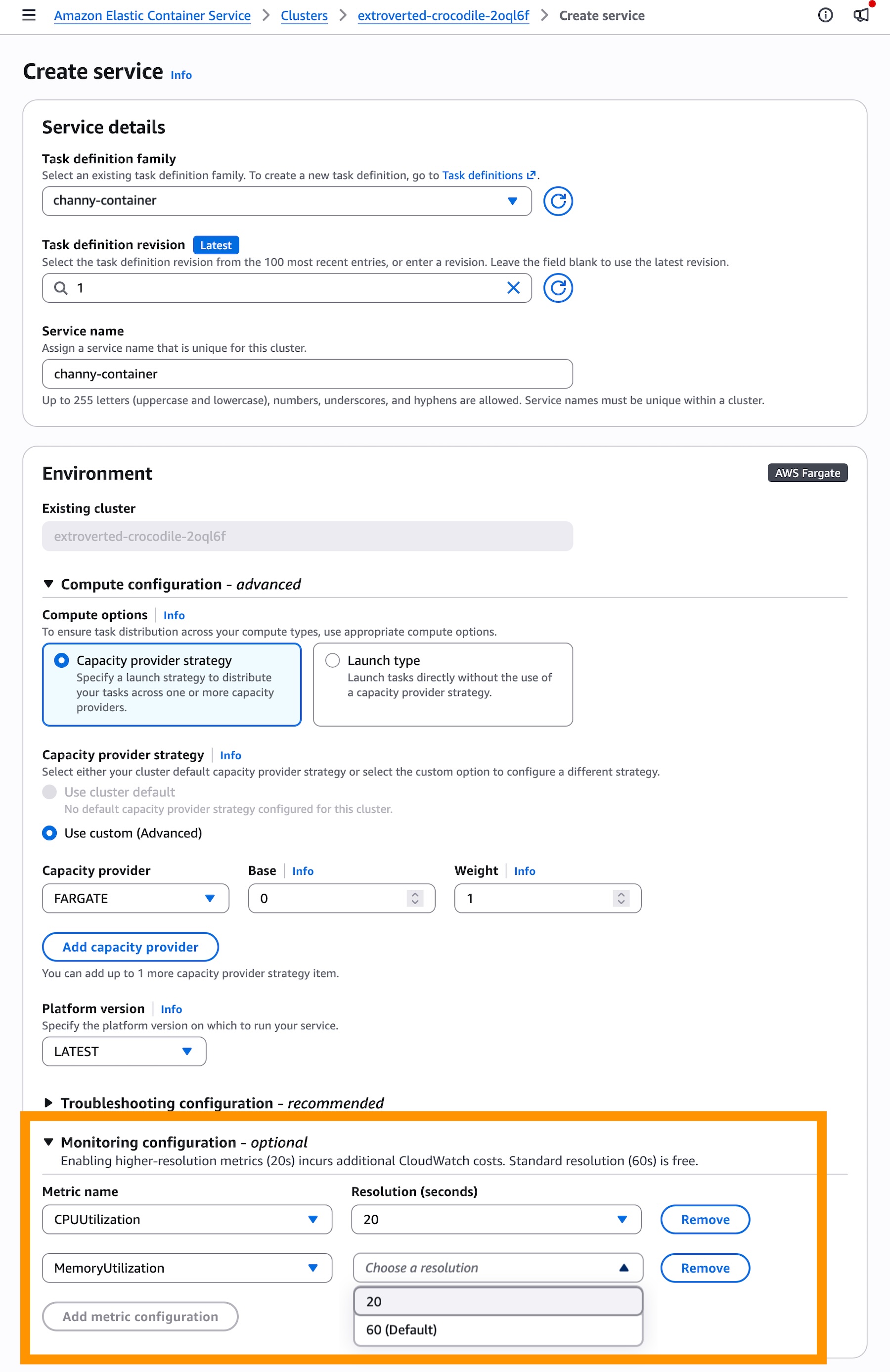
- Configuration: Within the ECS Console, navigate to the "Monitoring configuration" section.
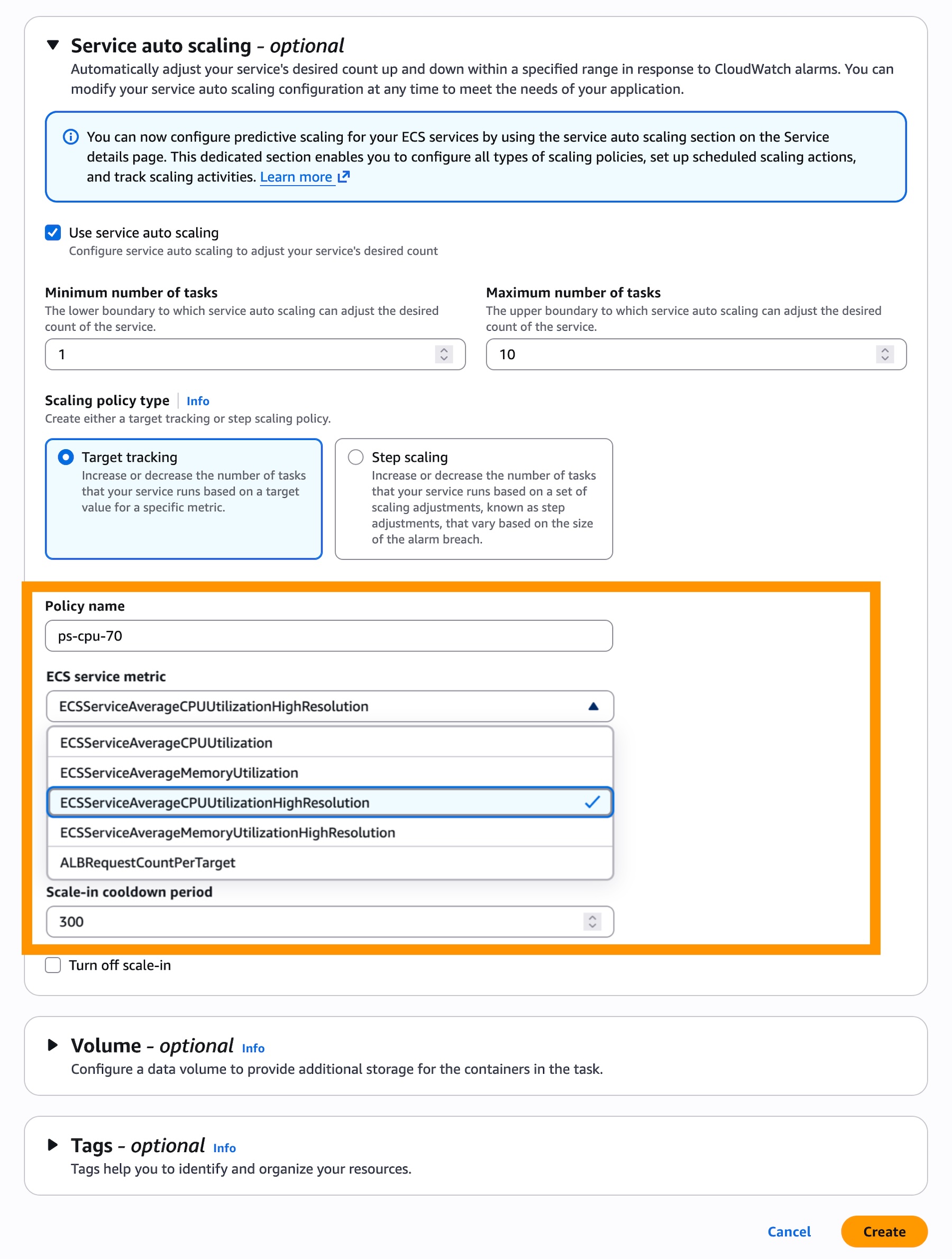
- Metric Selection: Select the 20-second resolution metrics for CPU and Memory utilization (
ECSServiceAverageCPUUtilizationHighResolutionorECSServiceAverageMemoryUtilizationHighResolution). - Policy Integration: Update the "Target Tracking" policy to point to these new high-resolution metrics.
Financial Considerations
While the feature itself carries no additional service cost from ECS, users must be aware of the underlying economics. High-resolution CloudWatch metrics do incur additional charges compared to the standard 60-second resolution metrics. AWS advises teams to weigh the cost of additional monitoring against the potential revenue loss of slow scaling during peak traffic.
Implications for Modern Software Architecture
The implications of this update ripple across several areas of software development and infrastructure management.
1. Improved Resource Efficiency
By scaling faster, organizations can afford to run closer to the edge of their capacity. Previously, engineers might have set aggressive safety margins (over-provisioning) to account for the slow 363-second scale-out time. With the new 86-second trigger time, those safety buffers can be reduced, directly translating to lower compute costs.
2. Enhanced Resilience for Microservices
Microservices architectures often suffer from "cascading failure" scenarios. If one service in a chain slows down due to a lack of resources, it can cause timeouts in upstream services. The faster response time of the new ECS auto scaling acts as a buffer against these chain reactions, significantly hardening the resilience of complex, distributed systems.
3. Enabling "Burstier" Workloads
Many modern applications, such as serverless-style data processing or AI inference endpoints, are characterized by short, intense bursts of activity. This update makes ECS a much more viable platform for these types of workloads, which previously might have been relegated to AWS Lambda to avoid the cold-start and slow-scaling latency of traditional container services.
Official Perspective and Community Response
AWS Evangelist Channy Yun emphasized that this update is a direct response to customer feedback. "Our customers are constantly pushing the boundaries of what is possible with containerized workloads," Yun noted in the official announcement. "By providing the tools to detect and respond to load changes in near real-time, we are allowing developers to focus on application logic rather than managing infrastructure latency."
Early adopters in the AWS re:Post community have responded positively, particularly noting the ease of integration. However, some have highlighted the need for careful threshold tuning. Because the system is now much more sensitive to minor fluctuations (due to the 20-second interval), there is a risk of "flapping"—where the system scales up and down too rapidly if the target metrics are set too close to baseline noise. AWS suggests using a slightly higher "cooldown" period in conjunction with high-resolution metrics to mitigate this.
Future Outlook
As AWS continues to refine its container services, the industry is likely to see further integration of AI-driven insights into the scaling process. While 20-second resolution is currently the industry standard for high-performance scaling, the next logical step would be "proactive scaling" that leverages real-time stream processing from logs and network ingress points to trigger scaling before the metrics even reach a threshold.
For now, the move to 20-second metrics marks a maturation point for Amazon ECS. It signals that AWS is no longer just a platform for hosting containers, but a sophisticated, hyper-responsive ecosystem capable of keeping pace with the most demanding, high-traffic applications on the internet. Organizations currently running critical services on ECS should evaluate their existing scaling policies and consider migrating to high-resolution metrics to ensure they are capturing the full performance potential of their cloud infrastructure.