Microsoft Clarity Unveils Advanced Bot Analytics: A New Era for Webmaster Control
REDMOND, WA – In a significant stride towards empowering webmasters with unparalleled insights into their digital properties, Microsoft Clarity has rolled out an advanced feature within its Bot Analytics dashboard. This new functionality specifically identifies and quantifies bot requests that disregard a website’s robots.txt directives, marking a crucial enhancement for site owners grappling with the complexities of modern web traffic.
The announcement, delivered via a recent Microsoft Clarity blog post, details how the tool will now calculate and display these non-compliant bot requests as a distinct percentage of total bot activity over any given timeframe. This capability integrates seamlessly with Clarity’s existing suite of AI Visibility tools, which notably began showcasing the grounding queries behind AI citations in May. The update positions Clarity as an increasingly indispensable, and crucially, free resource for monitoring and understanding the often-opaque world of automated web crawlers.
The escalating volume of bot traffic, particularly from an expanding array of AI-driven agents, has long posed multifaceted challenges for website administrators. These challenges range from the erosion of server resources and the subsequent financial strain to the distortion of vital analytics data, making it difficult to discern genuine user engagement from automated interactions. Microsoft Clarity’s latest innovation directly addresses these concerns, offering a granular view of bot behavior that was previously difficult, if not impossible, to obtain without extensive manual log analysis.
This development is not merely a technical update; it represents a philosophical shift in how webmasters can approach bot management. By providing clear, actionable data on robots.txt violations, Clarity equips site owners with the intelligence needed to optimize site performance, safeguard data integrity, and ensure that their carefully constructed web infrastructure serves its intended purpose without undue interference from unruly automated visitors. The journey towards a more transparent and manageable web ecosystem continues, and Microsoft Clarity’s latest offering is a powerful testament to this ongoing evolution.
Main Facts: Unpacking Clarity’s Latest Bot Intelligence
Microsoft Clarity’s latest update introduces a powerful new dimension to its already robust Bot Analytics dashboard: the direct identification and quantification of bot requests that actively disregard a website’s robots.txt rules. This feature is designed to provide webmasters with a clearer, more immediate understanding of how automated agents interact with their sites, particularly concerning adherence to established crawl directives.
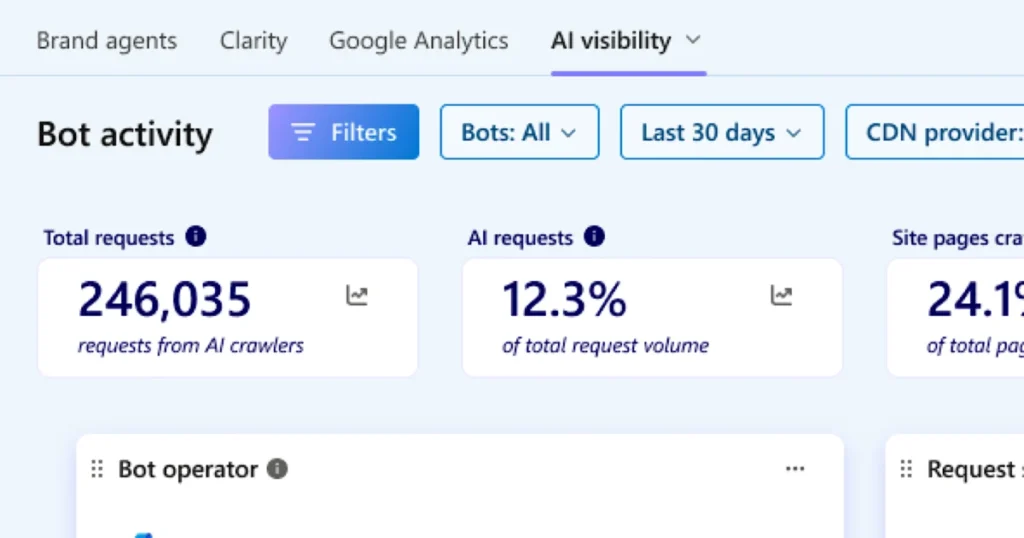
At its core, the new functionality operates by cross-referencing every bot request made to a Clarity-connected website against the site’s robots.txt file. If a bot attempts to access a path that has been explicitly disallowed by the site owner, Clarity flags this as a violation. These violations are then aggregated and presented as a percentage of the total bot activity observed over a user-defined period. This percentage metric offers a concise yet impactful summary of the compliance level among visiting bots.
This new data point is integrated within the broader AI Visibility tools dashboard, an area of Clarity that has seen continuous development, including the earlier introduction of insights into AI citation grounding queries. The integration ensures a unified perspective on advanced bot and AI interactions.
One of the standout features accompanying this update is the enhanced filtering capability. Site owners can now dissect bot activity based on several critical parameters:
- Bot Operator: Identifying the entity responsible for the bot (e.g., Google, Bing, OpenAI).
- Bot Name: Distinguishing specific crawlers (e.g., Googlebot, GPTBot).
- Request Activity Type: Categorizing the nature of the bot’s interaction.
- Requested URLs and Paths: Pinpointing the exact locations bots are attempting to access.
These filtering options are complemented by a unique side-by-side view, allowing webmasters to directly compare the behavior of generally compliant crawlers with those exhibiting robots.txt violations. This comparative analysis is instrumental in identifying patterns, understanding the intent behind non-compliance, and potentially differentiating between legitimate, albeit aggressive, crawlers and more malicious or resource-intensive bots.
Crucially, this advanced bot analytics feature is not automatically activated across all Clarity projects. It requires manual enablement by a project administrator within the AI Visibility section of Project Settings. Furthermore, its full functionality is contingent upon the website utilizing a supported Content Delivery Network (CDN) or, for WordPress users, employing the latest Microsoft Clarity plugin. The list of currently supported CDNs includes industry giants such as Fastly, Amazon CloudFront, Cloudflare, Azure Front Door, and Akamai. This requirement underscores the technical sophistication involved in accurately tracking and attributing bot requests at the network edge.
The "why" behind this feature is as important as the "what." In an era where AI crawlers are increasingly prevalent, consuming vast server resources and potentially skewing vital analytics, gaining granular visibility into their adherence (or lack thereof) to site rules is paramount. Microsoft Clarity, being a free service, offers an invaluable, no-cost mechanism for site owners to monitor this critical aspect of web management. While Clarity reveals that these requests occurred, it doesn’t delve into the reasons for the violations, leaving further investigative avenues open for site administrators.
It’s important to clarify a fundamental aspect of robots.txt: it is an advisory protocol, not a policing mechanism. It communicates preferences to bots, but it does not inherently block access. Therefore, Clarity’s new feature records requests that reached paths a site’s robots.txt disallows, rather than requests that were prevented from reaching those paths. This distinction is vital for understanding the nature of the data provided. This automated solution also addresses a significant pain point for large-scale websites: the impracticality and inefficiency of manually parsing server logs and testing URLs against robots.txt directives to identify non-compliant bot activity. Clarity automates this arduous process, saving countless hours and providing immediate, scalable insights.
Chronology: The Evolving Landscape of Bot Management and Clarity’s Role
The journey to Microsoft Clarity’s advanced bot analytics is rooted in a long-standing challenge for webmasters: managing automated traffic. For decades, the internet has been navigated by bots – from legitimate search engine crawlers indexing content to malicious scrapers and spambots. The robots.txt protocol, introduced in 1994, emerged as an early, albeit imperfect, solution for site owners to communicate their crawling preferences to these automated agents. However, its advisory nature meant that compliance was always voluntary, leading to a perpetual cat-and-mouse game between site owners and less scrupulous bots.
Early Struggles and Manual Interventions
In the early days of the web, and even into the 2000s, identifying and analyzing bot activity was largely a manual, labor-intensive process. Webmasters would frequently dive into raw server logs, sifting through millions of lines of data to identify user-agents, IP addresses, and requested URLs. This manual parsing, often done with basic scripting or text editors, was time-consuming, prone to error, and simply not scalable for websites experiencing significant traffic. The ability to cross-reference these requests with robots.txt directives to identify violations was an even more complex undertaking, reserved for highly technical administrators or specialized tools that were often expensive and complex to configure. The primary goal was often resource preservation and security, as rogue bots could disproportionately consume bandwidth and CPU cycles, or even exploit vulnerabilities.
The Rise of AI and Increased Bot Sophistication
The late 2010s and early 2020s ushered in a new era of bot activity, largely driven by advancements in Artificial Intelligence and Machine Learning. Beyond traditional search engine crawlers, a new breed of AI-powered bots began to emerge, designed for tasks such as data aggregation for large language models, competitive intelligence, content monitoring, and more. This surge in AI crawlers introduced new complexities:
- Increased Volume: The sheer number of diverse bots exploded, making identification harder.
- Resource Intensiveness: AI model training often requires vast amounts of data, leading to aggressive crawling patterns that can quickly overwhelm server resources.
- Blurred Lines: Distinguishing between beneficial, benign, and malicious bots became more challenging as their capabilities grew.
- Analytics Skewing: High volumes of bot traffic began to significantly distort traditional website analytics, making it harder for businesses to understand real user behavior, conversion rates, and engagement metrics.
Microsoft Clarity’s Evolution in AI Visibility
Against this backdrop, Microsoft Clarity, a free behavioral analytics tool, began to evolve its capabilities to address these modern challenges. Initially launched with features like heatmaps, session recordings, and user behavior analytics, Clarity recognized the growing need for insights into automated traffic.
- Early Bot Detection: Clarity already provided a basic level of bot detection, allowing site owners to filter out known bot traffic from their user behavior analytics. This was an essential first step in cleaning up data.
- May 2024: Grounding Queries for AI Citations: A significant precursor to the current update came in May 2024. Microsoft Clarity introduced the ability to show "grounding queries behind AI citations." This feature was designed to help webmasters understand how AI models were sourcing information from their sites, offering transparency into the content consumption patterns of AI agents and their potential impact on search and information retrieval. This marked a clear commitment by Microsoft to provide tools for navigating the AI-driven web.
- The Current Update:
robots.txtViolation Tracking: The latest announcement, detailing the tracking ofrobots.txtviolations, represents the natural progression of Clarity’s AI Visibility suite. It moves beyond simply identifying AI interactions to actively monitoring their adherence to site owner directives. This is a direct response to the increasing concerns around resource consumption and analytics integrity caused by bots that disregard established rules. By automating the identification of disallowed requests, Clarity directly addresses the scalability issue that plagued manual bot management for decades. It provides a real-time, aggregated view that was previously inaccessible to most webmasters, placing powerful analytical capabilities into the hands of a broader audience, all without cost.
This chronological progression highlights a clear trajectory: from basic bot filtering to understanding AI content consumption, and now to enforcing (or at least monitoring the adherence to) fundamental web protocols. Microsoft Clarity is steadily building a comprehensive toolkit designed to demystify automated web traffic and empower site owners in an increasingly complex digital ecosystem.
Supporting Data: Deep Dive into the Mechanism and Impact
The new robots.txt violation tracking feature in Microsoft Clarity is built upon a sophisticated technical framework that provides webmasters with detailed, actionable intelligence. Understanding its mechanics, requirements, and inherent limitations is crucial for leveraging its full potential.
How the Violations View Functions
When a bot initiates a request to a website that is integrated with Microsoft Clarity, the tool springs into action. Each incoming bot request is subjected to a rigorous check against the site’s robots.txt file. This file, typically located at the root of a website (e.g., www.example.com/robots.txt), contains directives that instruct crawlers about which areas of the site they are permitted or disallowed from accessing.
- Path Comparison: Clarity specifically analyzes the requested URL path from the bot and compares it against the
Disallowdirectives listed in therobots.txtfile. - Violation Identification: If the requested path matches a
Disallowrule, Clarity registers this as arobots.txtviolation. - Quantification: These identified violations are then calculated. The total number of disallowed requests is measured against the overall volume of bot activity recorded for a specified time frame (e.g., daily, weekly, monthly). This ratio is then expressed as a clear, digestible percentage, providing an immediate snapshot of bot compliance. For example, if 10,000 bot requests were observed, and 500 of them targeted disallowed paths, the violation rate would be 5%.
This automated process eliminates the need for manual parsing of server logs, a task that, for even moderately trafficked websites, could involve sifting through gigabytes of data and thousands upon thousands of individual requests.
Granular Filtering and Comparative Analysis
Clarity’s strength lies not just in identifying violations but in providing the tools to analyze them deeply. The dashboard offers comprehensive filtering options:
- Bot Operator & Name: This allows site owners to differentiate between, for instance, Googlebot and GPTBot, or identify less reputable crawlers. Knowing the operator can inform decisions about whether to block an entire range of IPs or to adjust
robots.txtdirectives more specifically. - Request Activity Type: This categorizes the nature of the bot’s interaction, helping to understand if bots are just crawling, attempting to submit forms, or exhibiting other behaviors.
- Requested URLs and Paths: This granular detail is critical. It allows webmasters to see which specific pages or directories are being targeted despite disallowances. This could highlight attempts to access sensitive areas like
/wp-admin/for WordPress sites, private user data, or API endpoints.
Perhaps most insightful is the side-by-side view, which enables a direct comparison between bots that are generally known to follow robots.txt rules (e.g., major search engine crawlers) and those that frequently violate them. This visual comparison can reveal stark differences in behavior and help pinpoint problematic bots. For instance, a site owner might observe that Googlebot consistently adheres to directives, while a lesser-known crawler repeatedly targets disallowed paths, indicating a potential need for further investigation or even IP-level blocking.
Activation and Supported Infrastructure
The feature’s reliance on specific infrastructure is key to its accuracy and performance. To activate the robots.txt violation tracking, a project administrator must navigate to the AI Visibility section within Clarity’s Project Settings.
The requirement for a supported CDN (Content Delivery Network) is due to the nature of how bot requests are intercepted and analyzed at the network edge before they hit the origin server. CDNs act as intermediaries, caching content and routing traffic, making them ideal points for monitoring and filtering. The currently supported CDNs include:
- Fastly
- Amazon CloudFront
- Cloudflare
- Azure Front Door
- Akamai
For WordPress sites, the latest Microsoft Clarity plugin provides the necessary integration, abstracting the CDN requirement for this specific platform. This broad support ensures that a significant portion of the web can leverage this new capability.
Why This Data Matters: Resource, Accuracy, and Strategy
The implications of this data extend across several critical areas for website management:
-
Server Resource Conservation: Every bot request consumes server resources—bandwidth, CPU cycles, database queries. Bots ignoring
robots.txtdirectives can disproportionately drain these resources by crawling irrelevant or restricted areas. For high-traffic sites, this translates directly into increased hosting costs and potential performance degradation for legitimate users. Identifying and mitigating these violations can lead to significant cost savings and improved site speed. -
Analytics Accuracy: Unwanted bot traffic can severely skew website analytics. Metrics like page views, bounce rate, session duration, and conversion rates become unreliable when a substantial portion of the activity comes from automated agents. By identifying and quantifying
robots.txtviolations, webmasters can gain a clearer picture of how much bot activity is infiltrating their "user" data, allowing for more accurate reporting and better-informed business decisions. -
SEO and Content Strategy: While
robots.txtis primarily for crawler directives, consistent violations by certain bots could indirectly impact SEO. If sensitive or private content is repeatedly crawled despite being disallowed, it raises questions about data privacy and potentially unwanted indexing. More importantly, understanding which bots respect directives can inform futurerobots.txtstrategy and content organization. -
Proactive Security Posture: While
robots.txtdoesn’t block access, persistent attempts to crawl disallowed paths can be an indicator of more malicious intent, such as vulnerability scanning, content scraping, or data exfiltration. The ability to quickly identify such patterns allows site owners to take proactive security measures, such as IP blocking or implementing Web Application Firewall (WAF) rules.
The Advisory Nature of robots.txt and Clarity’s Role
It is paramount to reiterate that robots.txt is an advisory protocol. It is a set of guidelines that request bots to behave in a certain way; it does not enforce these requests at the server level. Unlike a .htaccess file or a firewall, which can actively deny access based on rules, robots.txt relies on the good faith and programming of the bot operator.
Therefore, Microsoft Clarity is not stopping disallowed requests. Instead, it is recording requests that successfully reached paths that were explicitly disallowed by the site owner’s robots.txt file. This distinction is critical. Clarity provides the evidence of non-compliance, empowering the site owner to then take further action, such as contacting the bot operator, adjusting firewall rules, or implementing other security measures. The tool acts as a highly effective auditing and reporting mechanism, shining a light on behavior that was previously hidden or too complex to easily uncover.
Official Responses: Microsoft’s Vision for Webmaster Empowerment
The introduction of robots.txt violation tracking in Microsoft Clarity is more than just a new feature; it reflects a broader strategic vision from Microsoft regarding the future of web management, particularly in an era increasingly defined by artificial intelligence. While there haven’t been direct quotes from Microsoft executives beyond the blog post itself, the implied rationale and objectives are clear.
Addressing Webmaster Pain Points
Microsoft’s ongoing investment in Clarity, and specifically in its AI Visibility tools, signals a keen awareness of the evolving challenges faced by webmasters. The official blog post implicitly frames this update as a direct response to the "concerns around AI crawlers chewing through server resources and skewing analytics." This acknowledgment highlights Microsoft’s commitment to providing practical solutions for real-world problems. For years, the inability to easily quantify and analyze robots.txt violations has been a significant pain point, leading to resource wastage and data inaccuracies. By automating this process, Microsoft is directly alleviating a substantial burden on site administrators.
Empowering with Free, Accessible Tools
A core tenet of Microsoft Clarity’s strategy is its accessibility. The fact that Clarity remains a free service is a powerful statement. In a market where many advanced analytics and bot management solutions come with hefty price tags, Microsoft is positioning Clarity as an indispensable, no-cost alternative. This democratizes access to sophisticated web analytics, allowing even small businesses and independent webmasters to gain insights that were previously only available to larger enterprises with dedicated budgets for premium tools. The official communication consistently emphasizes this "no-cost way to keep an eye on whether crawlers honor those rules," underscoring Microsoft’s commitment to supporting the broader web ecosystem.
Fostering a Healthy Web Ecosystem
The move also subtly contributes to fostering a healthier, more transparent web environment. By making bot non-compliance visible and measurable, Microsoft encourages greater accountability among bot operators. While Clarity doesn’t "police" the web, it provides the data that allows site owners to identify and potentially address problematic bots. This could, in the long run, encourage bot developers to ensure their crawlers are more compliant with robots.txt directives, knowing that their behavior can now be easily monitored. This aligns with Microsoft’s broader efforts in web standards and responsible AI development.
Integration and Future Vision
The seamless integration of this new feature into the existing AI Visibility dashboard, alongside insights into AI citation grounding queries, points to a cohesive strategy. Microsoft appears to be building a comprehensive suite of tools within Clarity that specifically addresses the unique challenges posed by AI and automated web traffic. This suggests a forward-looking perspective, where Clarity aims to be the go-to platform for understanding not just human user behavior, but also the intricate dance between websites and the increasingly intelligent bots that crawl them. The official blog post alludes to the "more accurate, automated ways to assess how well robots.txt rules are being followed," implying a future where such assessments become standard practice rather than an arduous manual task.
In essence, Microsoft’s official stance, as communicated through the Clarity blog, is one of empowerment and enablement. They are providing webmasters with the intelligence and tools necessary to navigate a complex digital landscape, optimize their online presence, and maintain control over their digital assets, all while upholding their commitment to offering powerful, free solutions.
Implications: Reshaping Web Management and Bot Dynamics
The rollout of Microsoft Clarity’s robots.txt violation tracking capability carries significant implications for various stakeholders across the digital landscape, from individual webmasters to the broader bot ecosystem and even the future of web standards.
For Webmasters and Site Owners: Unprecedented Control and Clarity
The most immediate and profound impact will be felt by webmasters and site owners. This feature fundamentally shifts the paradigm of bot management from reactive guesswork to proactive, data-driven decision-making.
- Enhanced Visibility and Control: Site owners gain unprecedented visibility into which bots are respecting their rules and which are not. This intelligence is crucial for maintaining control over server resources and data integrity. They can now quantify the extent of non-compliance, moving beyond anecdotal evidence to hard data.
- Optimized Resource Allocation: By identifying bots that are unnecessarily crawling disallowed paths, webmasters can take targeted actions to mitigate resource drain. This could involve configuring server-level blocks for persistent offenders, adjusting WAF rules, or contacting bot operators directly. The financial savings from reduced bandwidth and CPU usage could be substantial for high-traffic sites.
- Improved Analytics Accuracy: The ability to clearly separate compliant and non-compliant bot activity helps in cleaning up analytics data. Site owners can better understand genuine human user behavior, leading to more accurate reporting on engagement, conversions, and user journeys. This empowers better marketing and business strategy.
- Proactive Security and Privacy: Persistent attempts to access disallowed paths can be an early warning sign of malicious activity, such as vulnerability scanning or data scraping. Clarity’s data allows for a more proactive security posture, enabling site owners to identify and address potential threats before they escalate. For sites handling sensitive information, this also bolsters data privacy efforts.
- Informed
robots.txtStrategy: The data can inform futurerobots.txtdirectives. If certain crucial areas are repeatedly being violated by specific bots, it might prompt a review of the directives themselves, or a decision to implement stricter server-side blocking for those areas. - Reduced Manual Labor: The automation of
robots.txtviolation detection eliminates the arduous and error-prone task of manual server log analysis. This frees up valuable time and technical resources for more strategic tasks.
For the Bot Ecosystem and AI Development: A Call for Accountability
The implications for bot operators and the wider AI development community are equally significant, albeit potentially more subtle in the short term.
- Increased Scrutiny and Accountability: With a widely adopted, free tool now capable of easily identifying
robots.txtviolations, bot operators will face increased scrutiny. This could lead to greater pressure to ensure their crawlers are compliant with standard web protocols. Non-compliant bots may find themselves more frequently blocked at the server level. - Potential for Behavioral Shifts: The "big question" posed in the original article remains: will making this behavior easier to measure actually change how crawlers behave? While
robots.txtis advisory, widespread reporting of non-compliance could incentivize ethical bot development. Reputation matters, and consistent disregard for directives could lead to a bot being perceived as less reputable or even malicious. - Impact on AI Training Data Sourcing: As AI models increasingly rely on vast datasets scraped from the web, the ability of webmasters to monitor and control this scraping becomes more pronounced. This could influence how AI companies approach data acquisition, potentially encouraging more transparent and compliant crawling practices.
- Evolution of Bot Identification: The detailed filtering capabilities in Clarity will likely push bot operators to ensure their user-agent strings are accurate and descriptive, allowing site owners to easily identify them.
For Microsoft Clarity and the Analytics Industry: Strengthening a Free Powerhouse
This update solidifies Microsoft Clarity’s position as a robust and highly competitive analytics tool, especially given its free nature.
- Enhanced Value Proposition: By offering a feature that addresses a critical and growing concern (bot management in the AI era) without cost, Clarity significantly boosts its value proposition. This could drive greater adoption among webmasters looking for powerful, yet accessible, tools.
- Competitive Edge: This specialized bot analytics capability gives Clarity a distinct edge against many other analytics platforms, some of which offer similar features only in premium tiers or through complex integrations.
- Driving Innovation: Microsoft’s continuous development of Clarity, particularly in the AI Visibility space, signals its commitment to innovation in web analytics. This could push other industry players to develop similar or even more advanced bot management features.
Broader Implications and the Future Outlook
The introduction of this feature is a step towards a more transparent and manageable internet. It highlights the ongoing tension between the open nature of the web and the need for site owners to control their digital property.
- Evolving Web Standards: While
robots.txtitself is unlikely to change dramatically overnight, the increased visibility of its observance (or lack thereof) might spark discussions about stronger, more enforceable web crawling protocols in the future. - The AI Frontier: As AI continues to integrate more deeply into web interactions, tools like Clarity will become increasingly vital. The future might see more advanced features, such as AI-powered anomaly detection for bot behavior, automated mitigation strategies, or even direct communication channels between webmasters and bot operators facilitated by analytics platforms.
- Ethical AI and Web Interaction: The data provided by Clarity contributes to a broader conversation about ethical AI development and responsible web interaction. It underscores the responsibility of AI developers to ensure their automated agents respect the implicit and explicit rules of the internet.
In conclusion, Microsoft Clarity’s new robots.txt violation tracking feature is more than just a technical enhancement; it is a foundational shift in how webmasters can understand, manage, and ultimately control their digital presence in an increasingly automated and AI-driven world. It empowers them with critical data, fosters greater accountability in the bot ecosystem, and solidifies Clarity’s role as a leading, accessible tool for navigating the complexities of the modern web. The biggest question remains, as Microsoft itself noted: whether easier measurement will ultimately translate into changed behavior among crawlers, or simply provide a clearer record of the ongoing digital dance.