The Architecture of Failure: Why Tool Design is the True Bottleneck for AI Agents
In the rapidly evolving landscape of generative AI, the industry has spent significant cycles chasing "model capability"—the quest for more intelligent, reasoning-capable, and context-aware Large Language Models (LLMs). Yet, as organizations move from experimental chatbots to production-grade AI agents capable of executing tasks, a harsh reality has emerged: most agent failures are not caused by the model’s inability to reason, but by the flawed interfaces—the "tools"—they are forced to use.
When an AI agent fails to complete a task, the diagnostic reflex is often to swap in a more powerful model. However, developers are increasingly discovering that a model is only as effective as the tools it is granted. If the interface is opaque, ambiguous, or error-prone, even the most sophisticated frontier model will struggle to navigate it. This article explores the root causes of AI agent failure and outlines the design patterns that transform fragile prototypes into resilient, enterprise-ready systems.
The Misconception of Model Failure
The assumption that "smarter models fix everything" is a fallacy that leads to bloated costs and persistent, unpredictable errors. An AI agent operates within a sandbox of definitions: tool names, descriptions, parameter schemas, and documentation. These elements serve as the agent’s entire sensory and motor system.
When a tool’s definition is vague, the agent must guess the intent. When an API is exposed without a thoughtful wrapper, the agent is bombarded with irrelevant, noisy data. These are not failures of intelligence; they are failures of information architecture. To build reliable agents, developers must treat tool design as a first-class engineering discipline, prioritizing clarity, constraint, and predictability over raw model power.
Chronology of an Agent Failure: A Case Study
Consider the lifecycle of a typical "failing" agent. Initially, the agent is deployed with a broad, multi-functional tool—for instance, a generic manage_customer function. Early testing shows success, but as the agent is tasked with more complex workflows, the error rate climbs.
- The Discovery Phase: The agent receives a prompt to suspend an account. Because the tool handles creation, deletion, and updates under one umbrella, the agent struggles to map the specific intent to the correct action parameter.
- The Interpretation Gap: The model receives a 500-error from a raw, unfiltered API backend. It lacks the context to understand if the error is a network glitch, a validation issue, or an invalid permission.
- The Loop of Doom: Lacking structured error feedback, the agent attempts to "self-correct" by retrying the same incorrect request, eventually exhausting the API rate limit or triggering an unintended state mutation.
- The Systemic Breakdown: Because the tool was not designed with idempotency in mind, the retry mechanism causes duplicate charges or redundant notifications, turning a minor technical glitch into a business-impacting event.
This sequence is rarely the result of a "stupid" model. It is the logical outcome of an interface that offered the model no guidance on how to succeed or how to recover when things went wrong.
Essential Patterns for Robust Tool Design
To mitigate these failures, engineers must adopt a rigorous set of design patterns that treat the LLM as a partner in a constrained, logical environment.
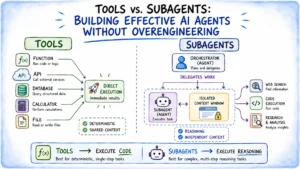
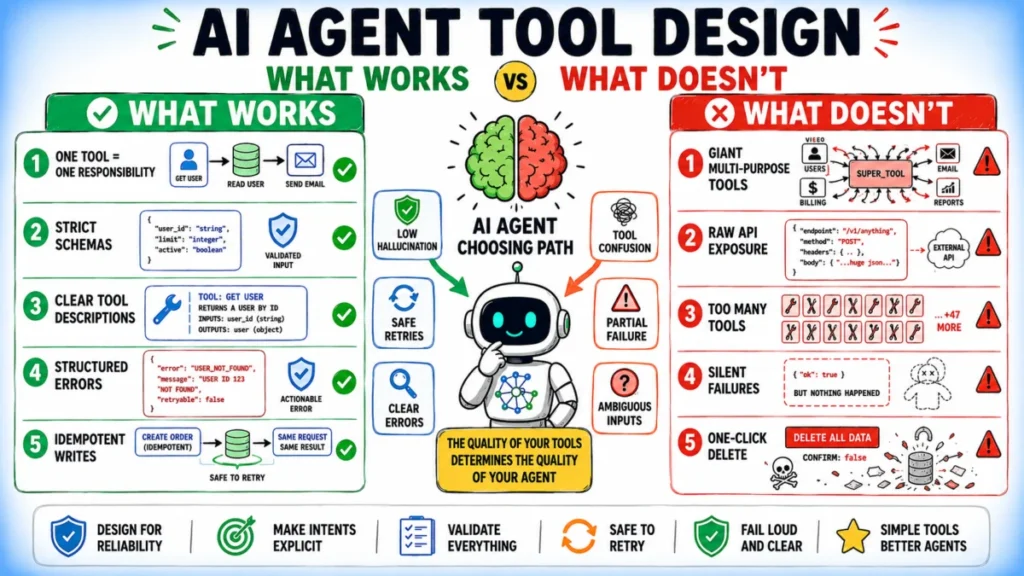
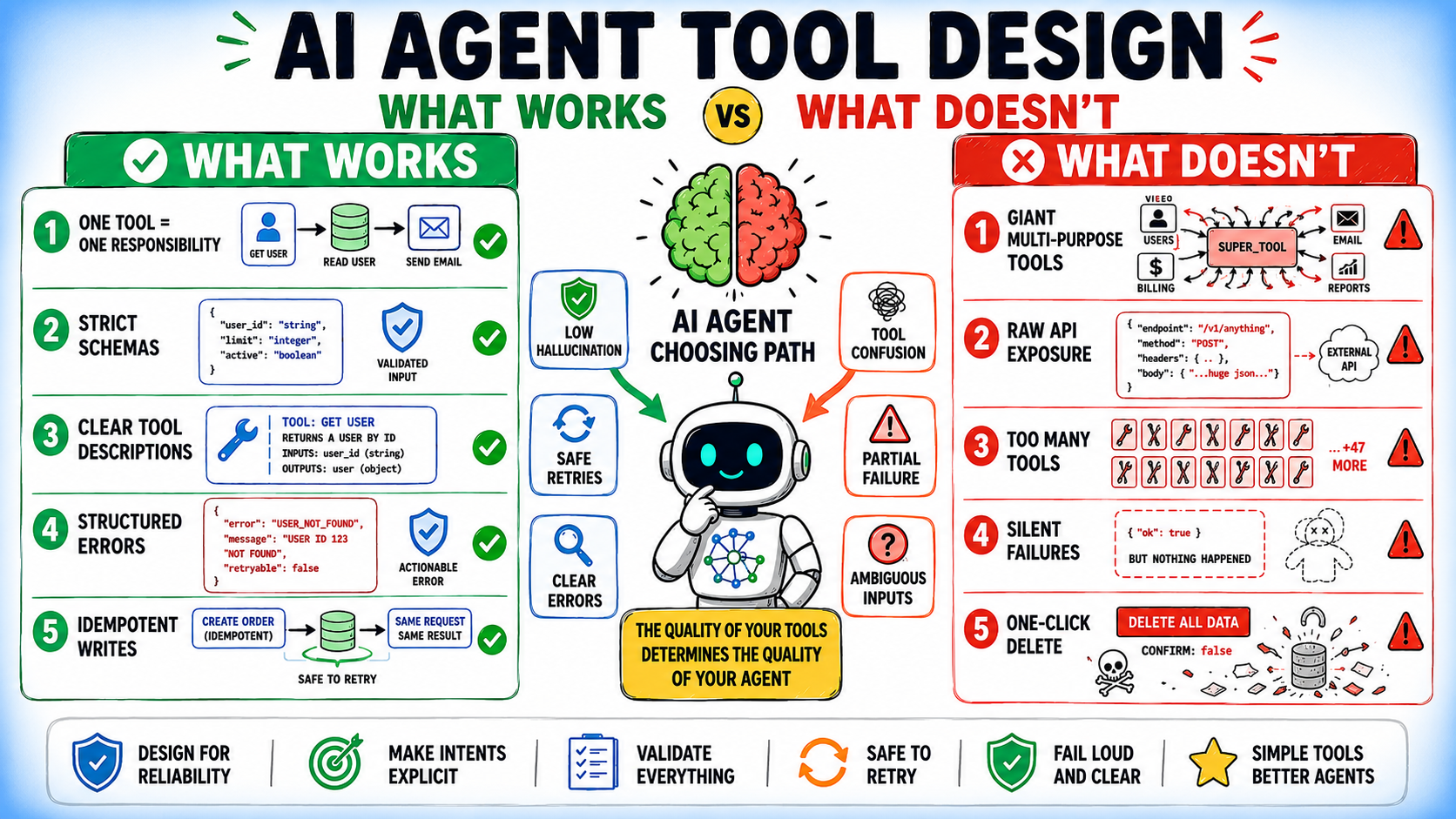
1. The Single Responsibility Principle (SRP)
In most agent systems, a tool should represent a single, clear operation. While it is tempting to group related functions into one "God-tool" to save on system prompt tokens, this backfires by increasing the search space for the model. When one tool handles multiple behaviors through an action parameter, the model must perform an extra layer of reasoning to decide which sub-function to trigger. By decomposing these into atomic tools—create_customer, get_customer, suspend_customer—the developer provides the model with unambiguous pathways.
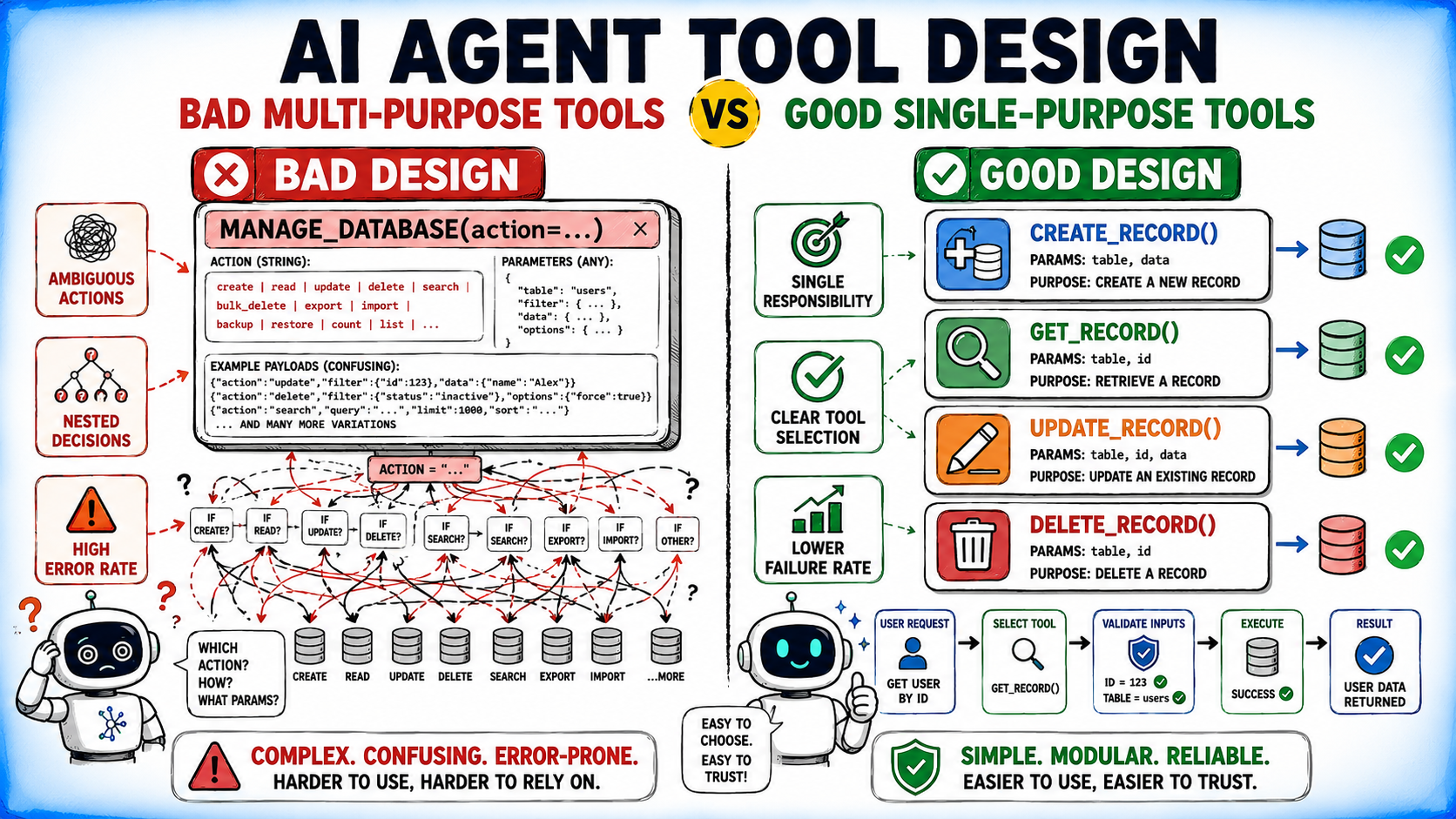
2. Constraints as Documentation
The most effective schemas are those that make invalid states impossible. By utilizing strict Pydantic models, Enums for selection lists, and regex patterns for data formats, you push validation to the boundary of the tool call. If the model generates an invalid argument, the system rejects it immediately with a clear error message, preventing the agent from ever interacting with the backend in an invalid state.
3. Purpose-Bound Descriptions
Tool descriptions are essentially the documentation that the model reads at runtime. Weak descriptions define only the what ("Searches the database"). Strong descriptions define the what, the when, and the when not. By including explicit boundaries—such as "Do not use this for real-time stock prices; use get_live_data instead"—you prevent the agent from choosing the wrong tool, effectively pruning the decision tree the model must navigate.
4. Structured Error Handling
Standard exceptions or stack traces are useless to an LLM. An agent needs actionable feedback. By returning a ToolError object that includes an error_code, a recoverable boolean, and a suggested_action, you enable the agent to make an informed decision. If a tool reports that an error is not recoverable, the agent can stop; if it is recoverable, the agent can pivot to a suggested alternative, such as querying a list of valid IDs before trying the call again.
Supporting Data: Why Complexity Breeds Inaccuracy
The relationship between tool catalog size and agent accuracy is inverse and well-documented. Research, such as the LongFuncEval study, confirms that as the number of available tools grows, the model’s performance degrades significantly, even with massive context windows.
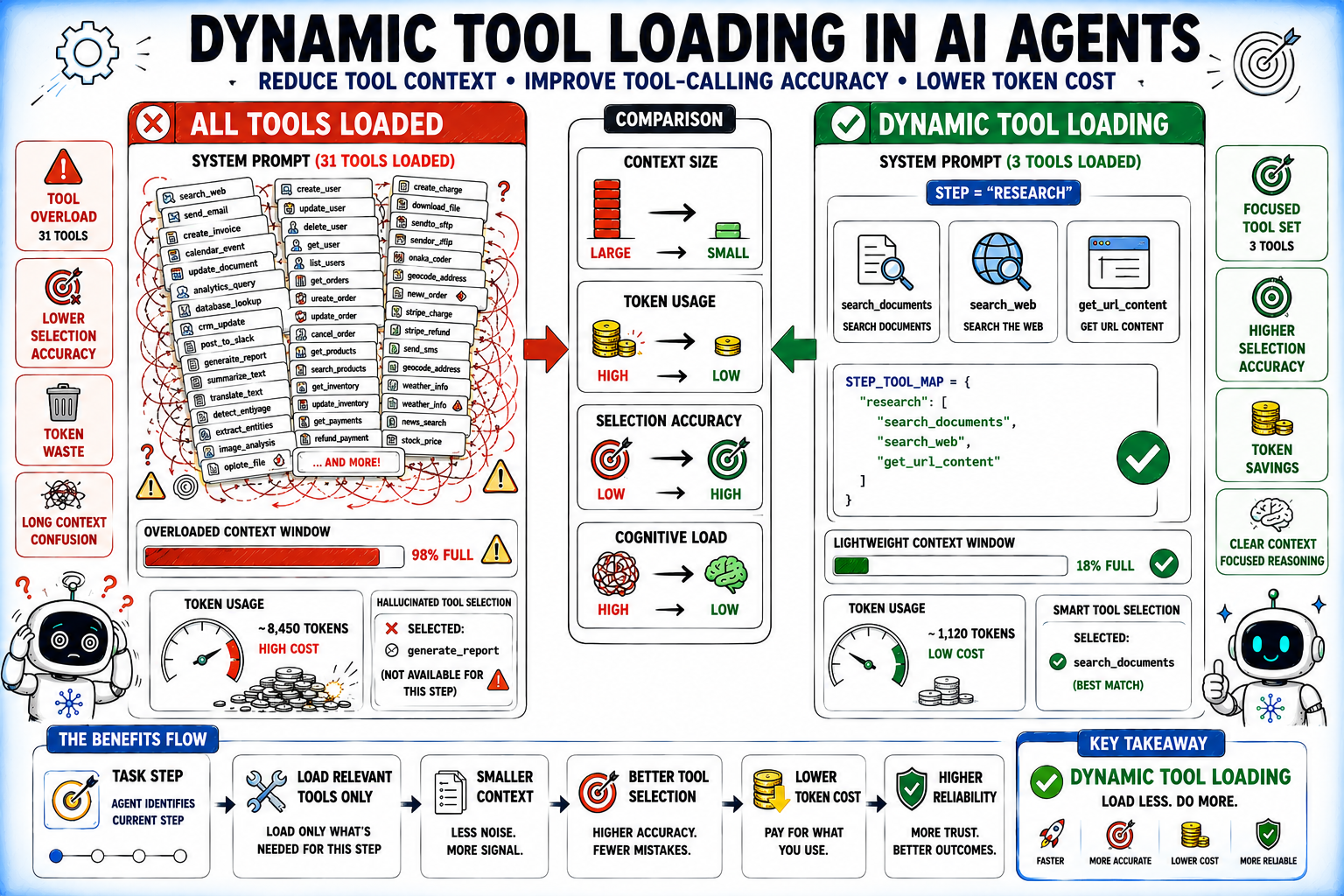
This is because the "attention" of the model is split across an increasing volume of metadata. The solution is Dynamic Tool Loading. By implementing a router that only injects tools relevant to the current stage of a workflow, developers can keep the context window clean and focused. For instance, if an agent is in the "Research" phase, it does not need access to "Write" or "Send" tools. Stripping away the irrelevant catalog reduces token costs and dramatically boosts selection accuracy.
Implications for Enterprise Deployments
For businesses, the implications of these design choices are profound. Relying on "off-the-shelf" API wrappers without custom agent-facing abstraction layers is a primary cause of production instability. Enterprise-grade AI agents require:
- Idempotency: Every state-changing tool must be idempotent. In an asynchronous agent environment, where network latency can cause timeouts, the system must guarantee that a second call with the same idempotency key does not duplicate an action like sending an email or processing a payment.
- Confirmation Gates: For destructive actions, the "Human-in-the-loop" pattern should be enforced at the architecture level. By requiring a two-step process—staging the action and then confirming it with a short-lived token—you prevent the agent from accidentally deleting records or executing irreversible transactions.
- Observability: Because agents are non-deterministic, auditability is essential. Every tool call must log its intent, its arguments, and the result, including whether it succeeded or failed and why. This allows developers to iterate on tool definitions based on actual agent performance data.
Conclusion
The transition from "chatting" with an LLM to "agentic" workflows requires a fundamental shift in how we build software interfaces. The model is not the problem; the model is the engine, but the tools are the transmission. If the transmission is poorly designed, the engine will fail to translate its power into movement.
By moving away from "thin wrappers" and "all-tool-loading" toward a paradigm of atomic, strictly typed, and self-documenting tools, developers can build agents that are not only more accurate but also more reliable and easier to maintain. As we look toward the future of autonomous systems, the winning companies will be those that realize that the key to AI success is not just having a smarter model, but a cleaner, more thoughtful interface for that model to inhabit.