
Beyond the Output: A Comprehensive Guide to Rigorous AI Agent Evaluation

In the current landscape of artificial intelligence development, the industry is undergoing a paradigm shift. For years, the gold standard for measuring the performance of Large Language Models (LLMs) was simple: feed the model a prompt, inspect the final output, and verify its accuracy. However, as developers pivot from static models to dynamic, autonomous AI agents capable of executing complex, multi-step workflows, this "black-box" evaluation method is no longer sufficient.
To build reliable AI systems, engineering teams must move beyond verifying final results and begin rigorously auditing the full execution process. This article outlines the systematic framework required to master AI agent evaluation, ensuring that your agents are not only functional but robust enough for production deployment.
The Core Challenge: Why Traditional Evaluation Fails Agents
Many teams currently evaluate AI agents as if they were simple chat-based models. They run a handful of test cases, check if the final response meets expectations, and assume the system is operational. This approach is fundamentally flawed because it ignores the inherent complexity of agentic behavior.
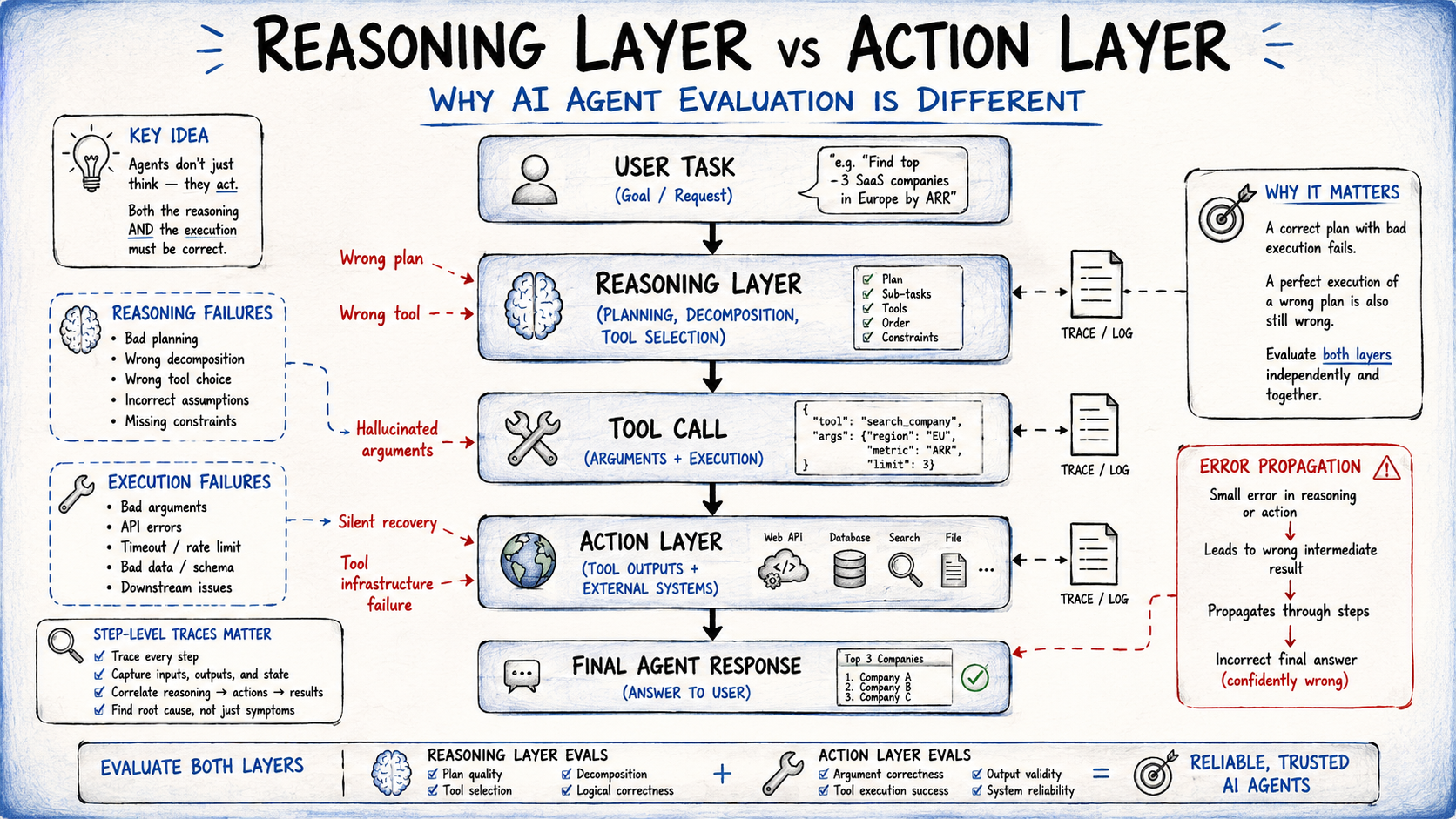
AI agents function through a series of interconnected layers: reasoning, tool selection, argument generation, and execution. A failure at any one of these stages can lead to a disastrous outcome. For instance, an agent might reason perfectly well about a user’s request, only to call a legitimate tool with malformed arguments. Alternatively, the agent might select the correct tool but fail to handle an API error gracefully. If you only look at the final output, you are left guessing where the breakdown occurred.
Understanding the Failure Surfaces
Agent evaluation must be bifurcated into two critical scopes:
- Task-Level Evaluation: This measures the end-to-end outcome. It tells you that something went wrong but provides little insight into why.
- Step-Level Traces: This is the diagnostic backbone of agent development. By capturing every tool call, argument, and intermediate thought, developers can pinpoint exactly where the agent went off track. Without these traces, debugging a production failure is akin to looking for a needle in a dark room.
Defining Success: The Foundation of Evaluation
Evaluation is only as valuable as the criteria it uses. A poorly defined benchmark will yield noisy data, leading teams to optimize for the wrong metrics. A well-formed evaluation task is defined as one where two independent domain experts would reach the same verdict on whether the agent "passed" or "failed."
The Anatomy of an Evaluation Suite
Before running any tests, teams must define the following:

- The Input: A clear, unambiguous user prompt or task requirement.
- The Constraints: Specific rules (e.g., "Must use the SQL database," "Cannot reference third-party websites").
- The Success Criteria: Explicit definitions of what constitutes a correct versus an incorrect execution path.
- Reference Solutions: A set of "known-correct" outputs that serve as the ground truth.
Teams should prioritize building tasks based on real-world usage data and historical failures rather than hypothetical scenarios. Evals are cumulative; the longer you wait to build them, the harder they become to implement as the agent’s complexity scales.
Grading the Action Layer: The Role of Determinism
Once the criteria are set, the next step is implementing an evaluation harness. The most efficient, cost-effective, and reproducible way to grade an agent’s "Action Layer" is through deterministic, code-based checks.
These graders function like unit tests in software engineering. They look for objective markers:
- Tool Usage Verification: Did the agent call the expected API?
- Argument Validation: Are the parameters passed to the tool within the expected format and schema?
- Output Format Checks: If the agent is meant to return a JSON object, does the output validate against the required schema?
While code-based checks are incredibly fast and reliable, they can be brittle. They are excellent for catching structural errors but fail to grasp the nuance of an agent’s reasoning or the quality of its conversational tone.
Model-Based Judges: Assessing Reasoning and Quality
For dimensions where deterministic code fails—such as empathy, tone, faithfulness to context, or logical flow—the industry has adopted LLM-as-a-Judge. By utilizing a high-performing language model to evaluate the outputs of a smaller agent, developers can gain qualitative insights that were previously impossible to automate.
Best Practices for LLM-as-a-Judge
- Structure Your Rubrics: Avoid vague instructions like "Is this response helpful?" Instead, decompose the task into specific dimensions: "Did the agent cite the retrieved document?" and "Did the agent avoid hallucinations?"
- Calibrate against Humans: Regularly validate your judge model against human-labeled samples. If the model and the humans diverge, the rubric—not the model—is usually the culprit.
- Partial Credit: In multi-component workflows, avoid binary pass/fail grading. If an agent performs four out of five steps correctly, that progress should be captured and acknowledged to help developers understand which parts of the agent are maturing.
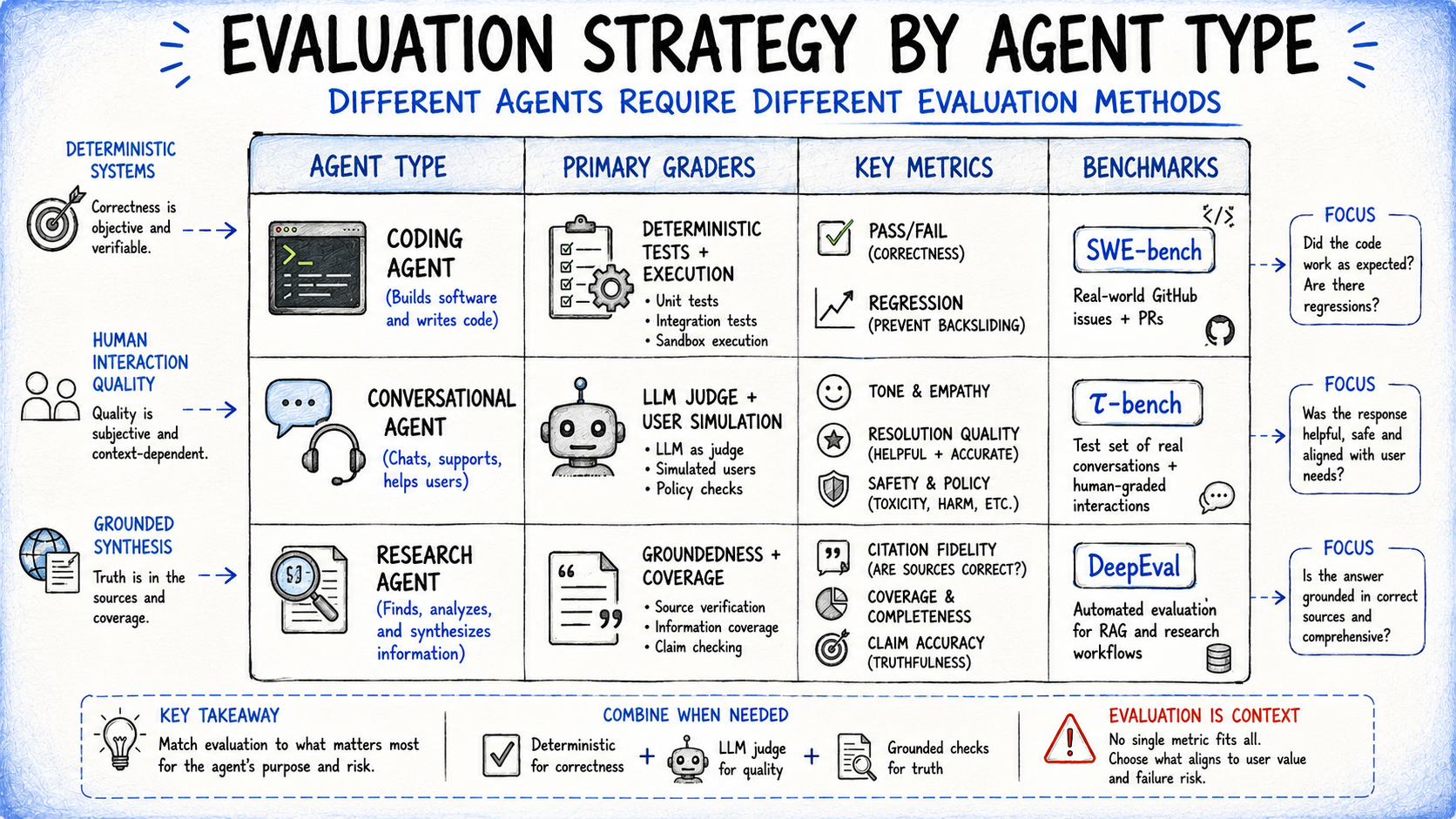
Tailoring Strategy to Agent Archetypes
Different agents possess different failure modes, and your evaluation strategy must reflect these nuances.
Coding Agents
For agents that write software, the evaluation should be heavily deterministic. Use benchmarks like SWE-bench to verify if the generated code compiles, passes unit tests, and fulfills the original issue ticket. Quality checks here should focus on security vulnerabilities and adherence to coding standards.
Conversational Agents
These agents require a more sophisticated, "simulated user" approach. The evaluation must assess whether the agent maintained the correct tone, resolved the user’s issue, and adhered to business policies. Tools like Chat-Bench utilize a second LLM to play the role of the user, creating a dynamic interaction loop that mimics real-world conditions.
Research Agents
The priority for research agents is grounding. Evaluation must focus on whether the claims made by the agent are directly supported by the retrieved sources. Coverage checks are vital here to ensure the agent has synthesized information from all relevant documents rather than cherry-picking data.
Navigating Non-Determinism: Pass@k and Pass^k
Because AI agents are inherently non-deterministic, they may produce different results for the same input across multiple runs. Relying on a single trial is a common pitfall that hides critical variability.
To combat this, teams should adopt probabilistic metrics:
- Pass@k: Measures whether the agent achieves the goal at least once in k attempts.
- Pass^k: Measures whether the agent succeeds in all k attempts.
If you are building an agent for a task where any successful outcome is acceptable, Pass@k is your north star. However, for high-stakes environments—such as medical advice or financial transactions—where consistency is mandatory, Pass^k is the only metric that matters.
Capability vs. Regression: A Dual-Suite Strategy
A robust evaluation system maintains two distinct categories of tests:
- Capability Evals: These are forward-looking. They test the boundaries of what the agent can do. These should be challenging, with lower pass rates, as they are designed to push the agent to learn new, complex behaviors.
- Regression Evals: These are backward-looking. They ensure that as you update the agent, you haven’t broken existing functionality. These should be near-perfect (100% pass rate) and serve as a "safety net" for the development team.
As a capability eval becomes easier over time, it should be promoted into the regression suite, and new, more difficult tasks should be introduced to maintain the challenge level.
Moving into Production: The Final Frontier
Development evals can only capture what you anticipate will fail. Real-world users, however, will expose your agent to edge cases you never imagined. A complete evaluation strategy must extend into production.
| Method | Role in Ecosystem |
|---|---|
| Automated Evals | High-frequency regression testing on every commit. |
| Production Monitoring | Real-time tracking of latency, token usage, and API error rates. |
| User Feedback | The ultimate arbiter of success; identifies "correct" but unhelpful responses. |
| Manual Transcript Review | Qualitative deep dives to calibrate automated grading systems. |
By integrating tools such as LangSmith, Arize Phoenix, Braintrust, or Langfuse for tracing, teams can bridge the gap between offline development and online performance.
Conclusion
The transition from LLMs to AI agents is not just a technological upgrade; it is a shift in responsibility. By moving away from outcome-only testing and adopting a rigorous, trace-based, multi-layered evaluation framework, engineering teams can build agents that are truly reliable.
The goal is not to eliminate all failures—that is impossible in a stochastic system—but to make those failures observable, measurable, and ultimately, fixable. As you refine your evaluation roadmap, remember that the most successful agent teams are those that view evaluation not as a hurdle, but as the very foundation of their product’s competitive advantage.







